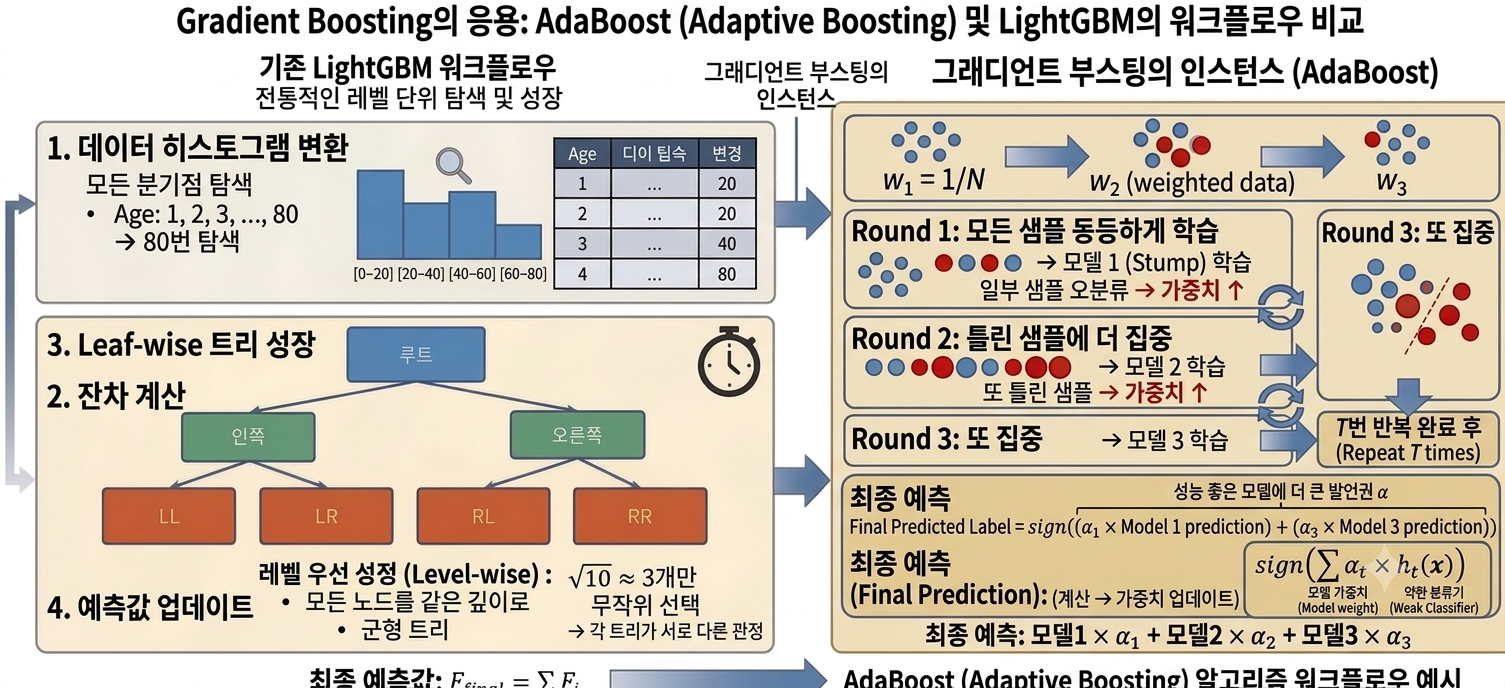
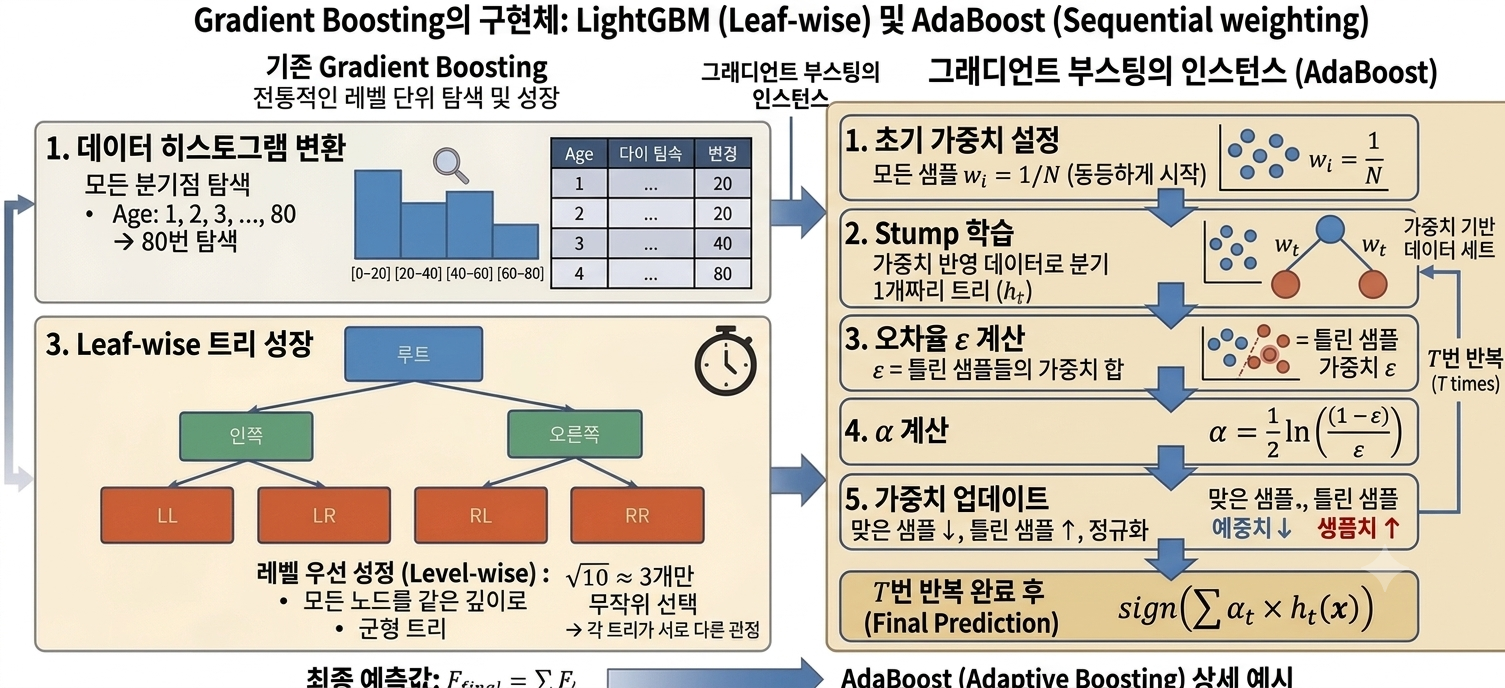
1. 왜 등장했는가
단일 Decision Tree는 훈련 데이터에 과적합되기 쉽고 성능 한계가 명확했습니다.
“약한 모델(weak learner) 여러 개를 순서대로 쌓으면 강한 모델이 된다”는 Boosting 이론을
최초로 실용화한 것이 AdaBoost (Adaptive Boosting) 입니다.
핵심은 이전 모델이 틀린 샘플에 더 집중해서 다음 모델을 학습시키는 것입니다. (Freund & Schapire, 1996)
2. 핵심 아이디어 — 오답 노트
AdaBoost는 본질적으로 틀린 문제를 반복해서 다시 푸는 오답 노트입니다.
각 Round의 모델은 depth=1짜리 트리인 Stump(스텀프) 입니다.
알고리즘은 각 Stump의 발언권 α를 데이터에서 자동으로 계산합니다.
3. 실제 예시로 보기 (분류)
예시 1 — 타이타닉 생존 예측 (분류)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| 훈련 데이터:
┌────────┬────────┬─────┬──────────┬──────────┐
│ 이름 │ 성별 │ 나이 │ 객실 등급 │ 생존 여부 │
├────────┼────────┼─────┼──────────┼──────────┤
│ Alice │ 여성 │ 29 │ 1등석 │ ✅ │
│ Bob │ 남성 │ 31 │ 3등석 │ ❌ │
│ Carol │ 여성 │ 45 │ 3등석 │ ✅ │
│ Dave │ 남성 │ 12 │ 2등석 │ ✅ │
│ Eve │ 남성 │ 38 │ 3등석 │ ❌ │
└────────┴────────┴─────┴──────────┴──────────┘
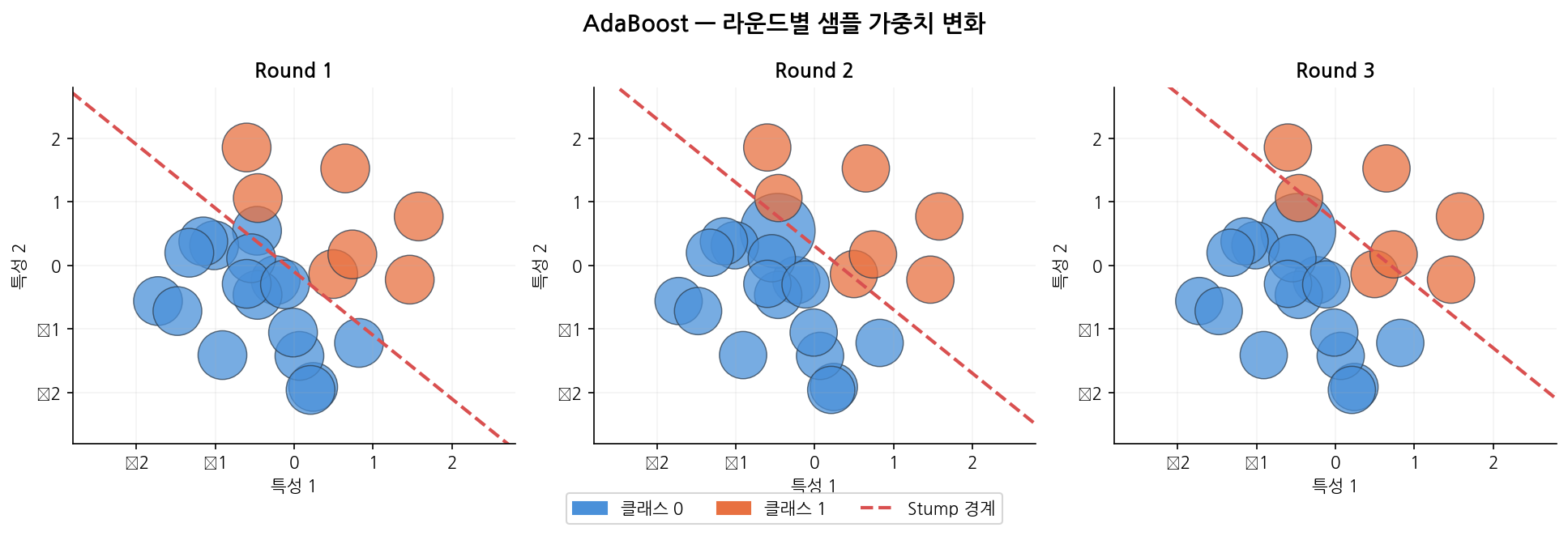
Round 1: Stump → "성별 = 여성?" 으로 분기
Bob, Eve 예측 실패 → 가중치 ↑
Round 2: 가중치 반영 → "나이 ≤ 15?" 로 분기
Dave 예측 성공
Round 3: "객실 = 1등석?" 로 분기
최종 예측 (새 승객: 남성, 12세):
Stump 1 (α = 0.20): ❌ 사망
Stump 2 (α = 1.10): ✅ 생존 ← 이 Stump가 발언권 높음
Stump 3 (α = 0.42): ✅ 생존
가중 합: -0.20 + 1.10 + 0.42 = +1.32 → ✅ 생존 예측
|
예시 2 — Stump의 구조
1
2
3
4
5
6
| Stump = depth=1 짜리 트리, 조건 딱 하나:
[성별 = 여성?]
/ \
YES NO
✅ 생존 ❌ 사망
|
4. 알고리즘 구성 요소
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| ┌──────────────────────┐
│ 초기 가중치 설정 │ ← 모든 샘플 wᵢ = 1/N (동등하게 시작)
└──────────┬───────────┘
│
▼
┌──────────────────────┐
│ Stump 학습 │ ← 가중치 반영 데이터로 분기 1개짜리 트리
└──────────┬───────────┘
│
┌──────────▼───────────┐
│ 오차율 ε 계산 │ ← ε = 틀린 샘플들의 가중치 합
└──────────┬───────────┘
│
┌──────────▼───────────┐
│ α 계산 │ ← α = ½ ln((1-ε)/ε)
└──────────┬───────────┘
│
┌──────────▼───────────┐
│ 가중치 업데이트 │ ← 맞은 샘플 ↓, 틀린 샘플 ↑, 정규화
└──────────┬───────────┘
│
T번 반복
│
▼
┌──────────────────────┐
│ 최종 예측 │ ← sign(Σ αₜ × hₜ(x))
└──────────────────────┘
|
| 구성 요소 | 설명 | 비유 |
|---|
| Stump | depth=1 트리. 조건 하나짜리 약한 모델 | 오답 노트의 한 문제 |
| 가중치 w | 각 샘플의 중요도. 틀릴수록 커짐 | 틀린 문제에 별표 |
| α (알파) | 각 Stump의 발언권. 성능 좋을수록 커짐 | 선생님 신뢰도 |
| 오차율 ε | 틀린 샘플들의 가중치 합 | 이번 시험 오답률 |
| T (반복 수) | Stump를 몇 개 쌓을지 | 오답 노트 총 페이지 수 |
5. 어떻게 α와 가중치를 계산하는가
5-1. 오차율 (ε) 계산
\[\epsilon_t = \sum_{i:\hat{y}_i \neq y_i} w_i^{(t)}\]
1
2
3
4
5
6
7
8
| 예시 (샘플 5개, 초기 가중치 0.2):
s1(0.2): 맞음
s2(0.2): 틀림 ←
s3(0.2): 맞음
s4(0.2): 틀림 ←
s5(0.2): 맞음
ε = 0.2 + 0.2 = 0.4
|
5-2. 모델 가중치 (α) 계산
\[\alpha_t = \frac{1}{2}\ln\!\left(\frac{1-\epsilon_t}{\epsilon_t}\right)\]
1
2
3
| ε = 0.4 → α ≈ 0.203 (그럭저럭)
ε = 0.1 → α ≈ 1.099 (잘함 → 발언권 높음)
ε = 0.5 → α = 0.000 (동전 던지기 → 무시)
|
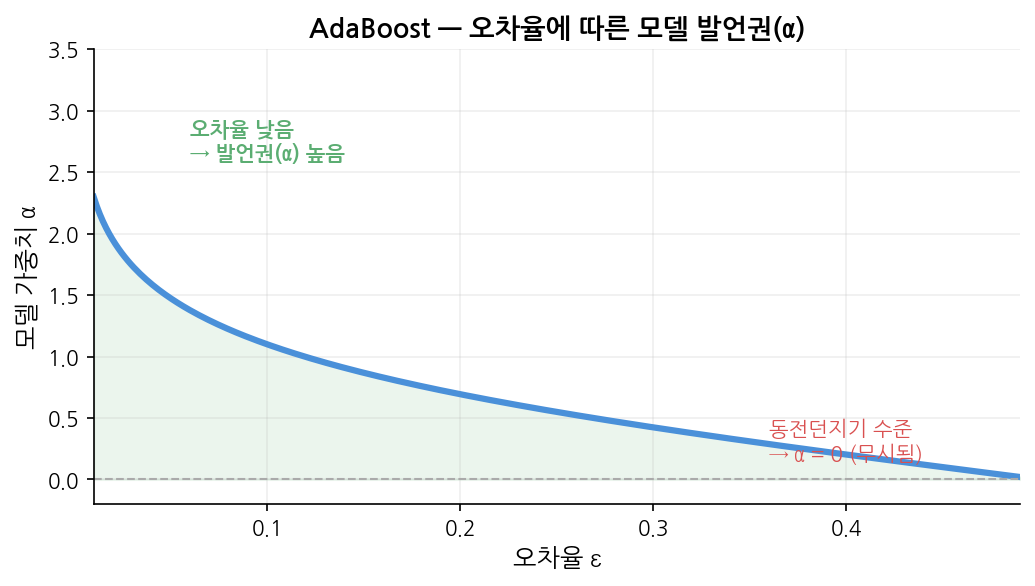
오차율 ε에 따라 α 값이 어떻게 바뀌는지, 그리고 라운드가 진행될수록 각 Stump의 발언권이 어떻게 쌓이는지 아래 그래프에서 확인할 수 있습니다.
읽는 법:
왼쪽 — ε이 0에 가까울수록(잘 맞출수록) α가 급격히 커집니다. ε=0.5(동전 던지기)면 α=0으로 발언권이 없습니다.
오른쪽 — 라운드가 진행될수록 α의 합산(발언권 총량)이 어떻게 누적되는지를 보여줍니다.
초반에 성능이 좋은 Stump일수록 α가 크고, 후반으로 갈수록 남은 오차만 보정하므로 α가 점점 작아집니다.
5-3. 샘플 가중치 업데이트
\[w_i^{(t+1)} \propto w_i^{(t)} \times \begin{cases} e^{-\alpha_t} & \text{맞은 샘플 (가중치 ↓)} \\ e^{+\alpha_t} & \text{틀린 샘플 (가중치 ↑)} \end{cases}\]
1
2
3
| α = 0.5일 때:
맞은 샘플: × e^{-0.5} ≈ × 0.607 (가중치 감소)
틀린 샘플: × e^{+0.5} ≈ × 1.649 (가중치 증가)
|
α가 클수록 (Stump 성능이 좋을수록) 가중치 변화가 더 극적입니다.
이것이 “좋은 Stump가 발견한 오류에 더 집중”하는 메커니즘입니다.
6. AdaBoost 장・단점
6-1. ✅ AdaBoost 장점
1
2
3
4
5
6
7
8
9
10
11
| 1. 하이퍼파라미터가 적음
→ n_estimators, learning_rate 두 개만 조정하면 됨
2. 과적합이 비교적 적음
→ 작은 데이터셋에서도 안정적으로 동작
3. 스케일링 불필요
→ Stump가 트리 기반이므로 거리 계산 없음
4. 빠른 베이스라인
→ 구현 단순, 즉시 사용 가능한 앙상블
|
6-2. ❌ AdaBoost가 약한 상황
1
2
3
4
5
6
7
8
9
| 1. 이상치(Outlier)가 있을 때
→ 계속 틀리는 이상치 샘플의 가중치가 폭발적으로 증가
→ 이상치에 모델 전체가 끌려감
2. 노이즈가 많은 데이터
→ 노이즈 샘플을 정답으로 학습하려 반복 집중 → 과적합
3. 병렬 처리가 필요할 때
→ 순차 학습 구조상 병렬화 불가 → 느림
|
6-2-1. 이상치 민감도 문제
AdaBoost의 가장 큰 약점입니다.
이상치 샘플이 매 Round마다 계속 오분류되면:
1
2
3
| Round 1: 가중치 0.20 → 0.35
Round 2: 가중치 0.35 → 0.61
Round 3: 가중치 0.61 → 1.06 ← 전체를 지배하기 시작
|
이상치 하나의 가중치가 정상 샘플 전체를 압도하게 됩니다.
결국 모든 Stump가 이상치 하나를 맞추기 위해 학습되어 성능이 급락합니다.
해결책 :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| # 방법 1: learning_rate 낮추기 (가중치 변화 완화)
ada = AdaBoostClassifier(
estimator=DecisionTreeClassifier(max_depth=1),
learning_rate=0.1, # 기본값 1.0 → 낮출수록 보수적
n_estimators=500,
random_state=0
)
# 방법 2: GridSearchCV로 최적값 탐색
from sklearn.model_selection import GridSearchCV
param_grid = {
'n_estimators': [50, 100, 200, 300],
'learning_rate': [0.01, 0.1, 0.5, 1.0]
}
ada_cv = GridSearchCV(
AdaBoostClassifier(estimator=DecisionTreeClassifier(max_depth=1), random_state=0),
param_grid,
cv=5,
scoring='roc_auc'
)
ada_cv.fit(X_train, y_train)
print(f"Best params : {ada_cv.best_params_}")
print(f"Best AUC : {ada_cv.best_score_:.4f}")
|
n_estimators 값에 따라 훈련/테스트 AUC가 어떻게 달라지는지 확인해보세요.
읽는 법:
파란선(훈련)은 라운드가 늘어날수록 계속 오르지만,
주황선(테스트)은 특정 n_estimators 이후 정체되거나 소폭 하락합니다.
두 선이 벌어지기 시작하는 지점이 과적합의 시작점입니다.
learning_rate가 낮을수록 정체 지점이 오른쪽으로 이동하며 더 많은 Stump가 필요합니다.
7. 한눈에 요약
| 항목 | 내용 |
|---|
| 알고리즘 유형 | 지도학습 / 분류 & 회귀 모두 가능 |
| 핵심 아이디어 | 틀린 샘플 가중치 증가 → 다음 Stump가 집중 학습 |
| 기반 모델 | Decision Stump (depth=1 트리) |
| 최종 예측 | sign(Σ αₜ × hₜ(x)) 가중 합산 |
| 스케일링 필요? | ❌ 불필요 |
| 이상치 | ⚠️ 매우 민감 |
| 핵심 파라미터 | n_estimators, learning_rate |
| 실전 사용 | 빠른 베이스라인, 데이터가 깨끗할 때 |
8. 다른 알고리즘과 무엇이 다른가
Random Forest vs AdaBoost
1
2
3
4
5
6
7
| Random Forest (Bagging): AdaBoost (Boosting):
트리1 트리2 트리3 Stump1 → Stump2 → Stump3
↓ ↓ ↓ (순서 있음, 앞 결과가 뒤에 영향)
└──────┴──────┘
다수결 α₁×h₁ + α₂×h₂ + α₃×h₃
(병렬, 독립) (가중 합산, 순차)
|
| 항목 | Random Forest | AdaBoost |
|---|
| 학습 방식 | 병렬 (독립) | 순차 (의존) |
| 기반 모델 | 깊은 트리 | Stump (depth=1) |
| 과적합 제어 | 트리 수, max_depth | n_estimators, learning_rate |
| 이상치 민감도 | 낮음 | 높음 |
Random Forest가 독립적인 트리들의 다수결로 예측하는 반면,
AdaBoost는 “이전 모델이 틀린 것에 집중”하는 순차적 학습입니다.
깨끗한 데이터에서는 AdaBoost, 이상치가 많다면 Random Forest가 더 안정적입니다.
9. 코드로 보기 — 타이타닉 생존 예측
1
2
3
4
5
6
7
8
9
| from sklearn.ensemble import AdaBoostClassifier
AdaB = AdaBoostClassifier(
base_estimator = None, # 기본 분류기 지정
n_estimators = 50, # 기본 분류기의 개수
learning_rate = 1.0, # 학습률
algorithm = 'SAMME.R', # 분류기의 학습 알고리즘 지정
random_state = 0 # 고정값
)
|
| Parameters | Explanation | Default |
|---|
base_estimator | 기본 분류기 지정 | None |
n_estimators | 기본 분류기 개수 | 50 |
learning_rate | 학습률 | 1.0 |
algorithm | 분류기 학습 알고리즘을 지정 | ‘SAMME.R’ |
random_state | 고정값 | None |
base_estimator : 기본 분류기 지정n_estimator: 기본 분류기 개수learning_rate : 분류기 학습 알고리즘을 지정- Options
SAMME: 이산 데이터 처리SAMME.R: 실수형 데이터 처리Other Algorithms
9-1. 전처리 (짧게)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| import pandas as pd
from sklearn.model_selection import train_test_split
titanic = pd.read_csv('./Data/Titanic.csv')
titanic['FamSize'] = titanic['SibSp'] + titanic['Parch']
use_cols = ['Survived', 'Pclass', 'Sex', 'Age', 'FamSize', 'Fare', 'Embarked']
titanic = titanic[use_cols].dropna(subset=['Age'])
titanic['Age'] = titanic['Age'].astype(int)
titanic = pd.get_dummies(titanic, columns=['Pclass', 'Sex', 'Embarked'], drop_first=True)
y = titanic['Survived']
X = titanic.drop('Survived', axis=1)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=0)
# ⚠️ AdaBoost는 트리 기반 → 스케일링 불필요
# StandardScaler 생략
|
Note: AdaBoost는 Stump(트리 기반)를 사용하므로 특성 스케일에 영향을 받지 않습니다. StandardScaler가 필요 없습니다.
9-2. 모델 학습
1
2
3
4
5
6
7
8
| adab = AdaBoostClassifier(
base_estimator = None, # 기본 분류기 지정
n_estimators = 50, # 기본 분류기의 개수
learning_rate = 1.0, # 학습률
algorithm = 'SAMME.R', # 분류기의 학습 알고리즘 지정
random_state = 0 # 고정값
)
adab.fit(X_train, y_train)
|
9-3. 평가
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| from sklearn.metrics import (
accuracy_score, confusion_matrix,
classification_report, roc_auc_score
)
pred = adab.predict(X_test)
pred_prob = adab.predict_proba(X_test)[:, 1]
cfx = confusion_matrix(y_test, pred)
sensitivity = cfx[1, 1] / (cfx[1, 0] + cfx[1, 1])
specificity = cfx[0, 0] / (cfx[0, 0] + cfx[0, 1])
roc_auc = roc_auc_score(y_test, pred_prob)
print(f"Accuracy : {accuracy_score(y_test, pred) * 100:.2f}%")
print(f"Sensitivity : {sensitivity * 100:.2f}%")
print(f"Specificity : {specificity * 100:.2f}%")
print(f"ROC AUC : {roc_auc:.4f}")
print()
print(classification_report(y_test, pred, target_names=['Died (0)', 'Survived (1)']))
|
9-4. 학습 곡선 — n_estimators 영향 확인
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| import matplotlib.pyplot as plt
train_scores, test_scores = [], []
for n in range(1, 201):
adab_tmp = AdaBoostClassifier(
base_estimator = None, # 기본 분류기 지정
n_estimators = 50, # 기본 분류기의 개수
learning_rate = 1.0, # 학습률
algorithm = 'SAMME.R', # 분류기의 학습 알고리즘 지정
random_state = 0 # 고정값
)
adab_tmp.fit(X_train, y_train)
train_scores.append(roc_auc_score(y_train, adab_tmp.predict_proba(X_train)[:, 1]))
test_scores.append(roc_auc_score(y_test, adab_tmp.predict_proba(X_test)[:, 1]))
plt.figure(figsize=(8, 4))
plt.plot(train_scores, label='Train AUC', color='steelblue')
plt.plot(test_scores, label='Test AUC', color='tomato')
plt.xlabel('n_estimators')
plt.ylabel('ROC AUC')
plt.title('AdaBoost — 학습 곡선')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
|
두 곡선이 벌어지기 시작하는 지점이 최적 n_estimators입니다.
9-5. 특성 중요도
1
2
3
4
5
6
7
8
9
10
11
| import pandas as pd
importances = pd.Series(adab.feature_importances_, index=X.columns)
importances = importances.sort_values(ascending=True)
plt.figure(figsize=(7, 5))
importances.plot(kind='barh', color='steelblue')
plt.xlabel('Feature Importance')
plt.title('AdaBoost Feature Importance')
plt.tight_layout()
plt.show()
|