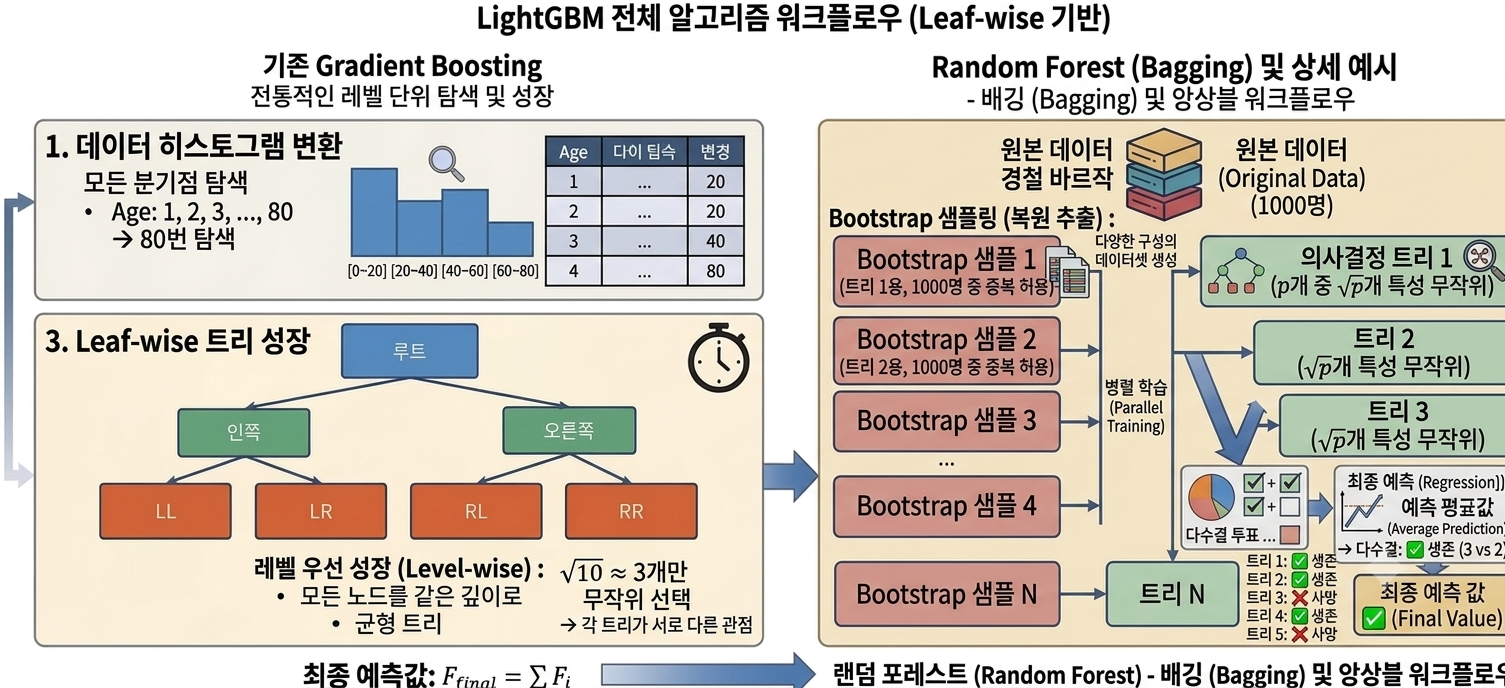
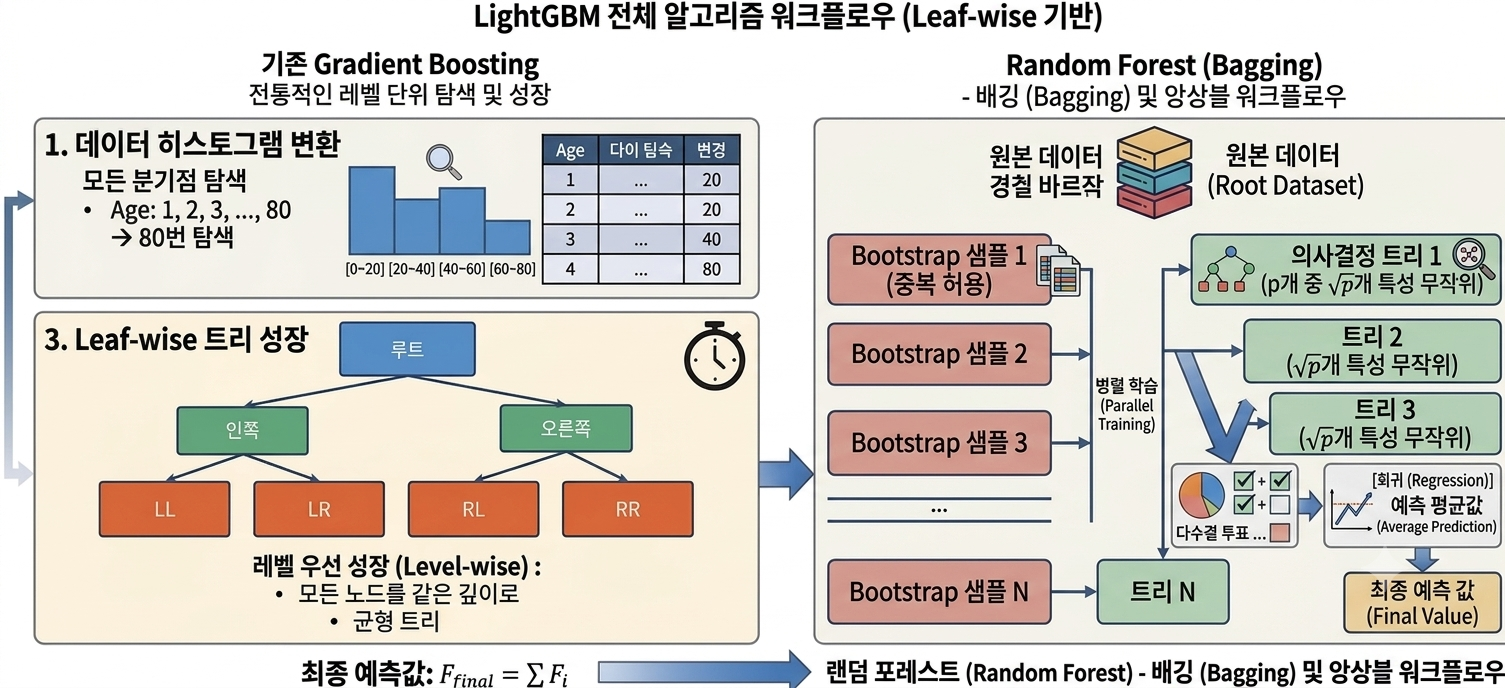
1. 왜 등장했는가
단일 Decision Tree는 훈련 데이터에 과적합되고, 데이터가 조금만 달라져도 트리 구조가 크게 변하는 불안정 문제가 있었습니다.
“여러 트리를 독립적으로 학습시켜 평균 내면 분산이 줄어든다”는 Bagging 아이디어에
각 트리가 서로 다른 특성 부분집합을 보도록 무작위성을 추가한 것이 Random Forest입니다. (Breiman, 2001)
단일 전문가의 판단보다 다양한 관점을 가진 전문가 집단의 합의가 더 신뢰할 수 있는 것과 같은 원리입니다.
2. 핵심 아이디어 — 다양한 전문가들의 다수결
Random Forest는 본질적으로 다양한 배경을 가진 전문가 패널의 투표입니다.
3. 실제 예시로 보기 (분류 / 회귀)
예시 1 — 타이타닉 생존 예측 (분류)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| 훈련 데이터:
┌────────┬────────┬─────┬──────────┬──────────┐
│ 이름 │ 성별 │ 나이 │ 객실 등급 │ 생존 여부 │
├────────┼────────┼─────┼──────────┼──────────┤
│ Alice │ 여성 │ 29 │ 1등석 │ ✅ │
│ Bob │ 남성 │ 31 │ 3등석 │ ❌ │
│ Carol │ 여성 │ 45 │ 3등석 │ ✅ │
│ Dave │ 남성 │ 12 │ 2등석 │ ✅ │
│ Eve │ 남성 │ 38 │ 3등석 │ ❌ │
└────────┴────────┴─────┴──────────┴──────────┘
트리 1 (Bootstrap + 특성: 성별, 나이):
→ "여성이면 생존" 학습
트리 2 (Bootstrap + 특성: 등급, 나이):
→ "1등석이면 생존" 학습
트리 3 (Bootstrap + 특성: 성별, 등급):
→ "여성+1등석이면 생존" 학습
...500개 트리...
새 승객 (여성, 1등석):
500개 트리 중 480개: ✅ 생존
500개 트리 중 20개: ❌ 사망
→ 최종: ✅ 생존 (96% 확률)
|
예시 2 — 집값 예측 (회귀)
1
2
3
4
5
| 트리 1 예측: 4.8억
트리 2 예측: 5.1억
트리 3 예측: 4.9억
...
500개 트리 평균: 4.93억 예측
|
4. 알고리즘 구성 요소
| 구성 요소 | 설명 | 비유 |
|---|
| Bootstrap 샘플링 | 복원 추출로 각 트리에 다른 데이터 | 다른 경험을 가진 전문가들 |
| 특성 무작위 선택 | 각 분기에서 √p개 특성만 사용 | 전문가마다 다른 관점 |
| 다수결/평균 | 모든 트리 결과 종합 | 패널 회의 최종 결정 |
| OOB (Out-of-Bag) | Bootstrap에 포함 안 된 샘플로 검증 | 자체 교차 검증 |
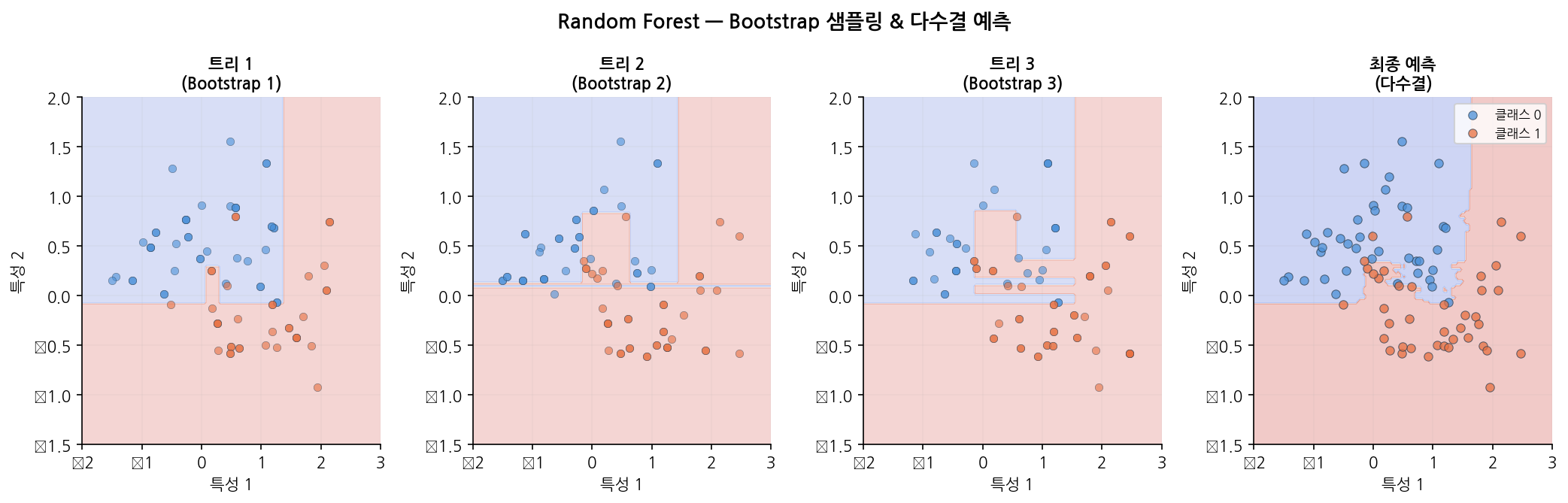
Bootstrap 샘플링과 다수결 투표 메커니즘을 아래 그래프에서 확인할 수 있습니다.
읽는 법:
왼쪽 — Bootstrap 샘플링: 원본 데이터에서 복원 추출하면 각 트리가 서로 다른 데이터 분포를 경험합니다.
오른쪽 — 다수결 투표: N개의 트리가 각자 예측한 결과를 집계합니다. 분류는 가장 많이 나온 클래스, 회귀는 평균값을 최종 예측으로 출력합니다.
5. 어떻게 다양성을 만드는가
5-1. Bootstrap 샘플링
1
2
3
4
5
6
7
| 원본: [A, B, C, D, E]
트리 1용: [A, A, C, D, B] (A 중복, E 없음)
트리 2용: [B, C, C, E, A] (C 중복, D 없음)
트리 3용: [A, D, E, E, C] (E 중복, B 없음)
각 트리가 서로 다른 데이터 분포를 경험
|
5-2. OOB (Out-of-Bag) 오차
Bootstrap 샘플링으로 약 37%의 샘플은 각 트리에 포함되지 않습니다.
이를 이용해 별도 교차 검증 없이 성능을 추정할 수 있습니다.
1
2
3
4
5
| 트리 1: [A,A,C,D,B] 학습 → B, E로 검증
트리 2: [B,C,C,E,A] 학습 → A, D로 검증
...
전체 OOB 정확도 = 각 샘플이 포함되지 않은 트리들의 평균 예측 정확도
|
6. Random Forest 장・단점
6-1. ✅ Random Forest 장점
1
2
3
4
5
6
7
8
9
10
11
12
13
| 1. 높은 예측 성능
→ 단일 Decision Tree보다 월등히 우수
2. 과적합에 강함
→ 다양한 트리의 평균 → 분산 감소
3. 특성 중요도 제공
→ 각 특성이 전체 트리에서 기여한 정도
4. OOB 오차로 교차 검증 대체 가능
5. 스케일링 불필요
→ 트리 기반
|
6-2. ❌ Random Forest가 약한 상황
1
2
3
4
5
6
7
8
9
10
11
| 1. 해석이 어려움
→ 수백 개 트리의 앙상블 → 블랙박스
2. 메모리 사용량 큼
→ 트리 수 × 트리 크기만큼 메모리 필요
3. 예측 속도 느림
→ 모든 트리를 통과 (단, 병렬화 가능)
4. 희소 고차원 데이터에 약함
→ 텍스트 등에서는 선형 모델이 우세
|
6-2-1. 트리 수 설정
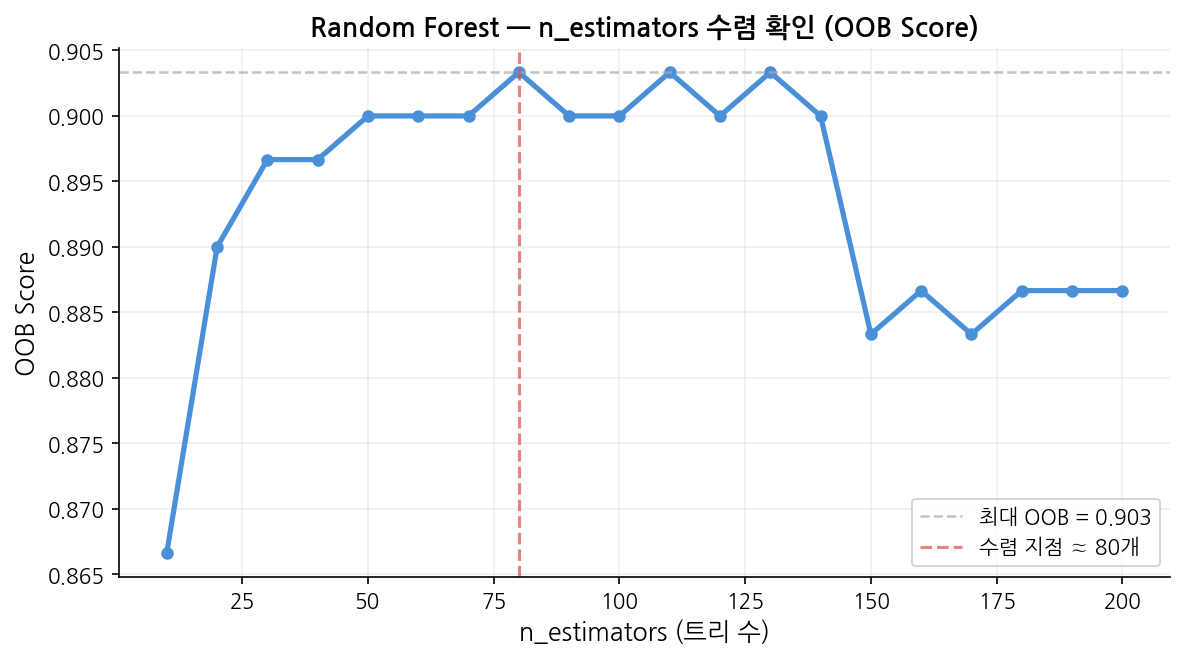
Random Forest의 핵심 파라미터 조정입니다.
n_estimators 가 너무 적으면 예측이 불안정합니다.
n_estimators 증가에 따른 OOB Score 수렴 과정을 아래 그래프에서 확인할 수 있습니다.
읽는 법:
x축은 n_estimators, y축은 OOB Score입니다.
초반에는 트리가 적어 성능이 불안정하지만, 특정 지점부터 OOB Score가 평탄해집니다.
이 수렴 지점이 충분한 n_estimators입니다. 이 이후로 트리를 늘려도 성능 향상이 없고 시간만 늘어납니다.
해결책 :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| # 방법 1: OOB Score로 수렴 확인
rf = RandomForestClassifier(n_estimators=200, oob_score=True, random_state=0)
rf.fit(X_train, y_train)
print(f"OOB Score: {rf.oob_score_:.4f}")
# 방법 2: GridSearchCV로 최적값 탐색
from sklearn.model_selection import GridSearchCV
param_grid = {
'n_estimators': [100, 200, 300],
'max_depth': [None, 5, 10, 20],
'min_samples_leaf': [1, 5, 10]
}
rf_cv = GridSearchCV(
RandomForestClassifier(random_state=0),
param_grid,
cv=5,
scoring='roc_auc'
)
rf_cv.fit(X_train, y_train)
print(f"Best params : {rf_cv.best_params_}")
print(f"Best AUC : {rf_cv.best_score_:.4f}")
|
7. 한눈에 요약
| 항목 | 내용 |
|---|
| 알고리즘 유형 | 지도학습 / 분류 & 회귀 모두 가능 |
| 핵심 아이디어 | Bootstrap + 특성 무작위 선택 → 다양한 트리 앙상블 |
| 기반 모델 | 깊은 Decision Tree |
| 최종 예측 | 다수결 (분류) 또는 평균 (회귀) |
| 스케일링 필요? | ❌ 불필요 |
| 핵심 파라미터 | n_estimators, max_features, max_depth |
| 실전 사용 | 높은 성능 + 안정성, 특성 중요도 분석 |
8. 다른 알고리즘과 무엇이 다른가
Decision Tree vs Random Forest vs Gradient Boosting
1
2
3
4
5
| Decision Tree: Random Forest: Gradient Boosting:
트리 1개 트리 N개 (병렬) 트리 N개 (순차)
빠름 보통 느림
과적합 ↑ 과적합 ↓ 과적합 ↓↓
해석 가능 블랙박스 블랙박스
|
| 항목 | Decision Tree | Random Forest | Gradient Boosting |
|---|
| 학습 방식 | 단일 | 병렬 (독립) | 순차 (의존) |
| 과적합 위험 | 높음 | 낮음 | 매우 낮음 |
| 해석 가능성 | ✅ 높음 | ⚠️ 어려움 | ⚠️ 어려움 |
| 학습 속도 | 빠름 | 보통 | 느림 |
9. 코드로 보기 — 타이타닉 생존 예측
1
2
3
4
5
6
7
8
9
10
11
| from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(
n_estimators = 200, # 생성할 트리 개수
max_depth = 10, # 각 트리의 최대 깊이
max_features = 'sqrt', # 분할 시 사용할 변수
min_samples_split = 2, # 노드 분할 최소 샘플 수
min_samples_leaf = 1, # Leaf 노드의 최소 샘플 수
random_state = 0, # random seed
n_jobs = -1 # 사용할 CPU 코어 개수 (-1: 전체 사용)
)
|
| Parameters | Explanation | Default |
|---|
n_estimators | 트리 개수 | 100 |
max_depth | 각 트리의 최대 깊이 | None |
max_features | 분할 시 사용할 변수 수 (sqrt 권장) | sqrt |
min_samples_split | 노드 분할 최소 샘플 수 | 2 |
min_samples_leaf | Leaf 노드 최소 샘플 수 | 1 |
criterion | 분할 기준 (gini or entropy) | gini |
bootstrap | Bootstrap 샘플링 사용 여부 | True |
class_weight | 클래스 가중치 (불균형 데이터 처리) | None |
random_state | 고정값 | None |
n_jobs | 사용할 CPU 코어 개수 (-1이면 전체) | None |
n_estimators : 여러 개의 Decision Tree를 몇 개 만들지 결정하는 파라미터(보통 100 ~ 300 | 데이터 크면 500 이상도 사용)- 값 변화별 효과
- 클수록 → 성능 안정화 (Variance 감소), 과적합 ↓
- 작을수록 → 모델 불안정, 성능 변동 큼
- 단점 → 학습 시간 증가
max_depth : 각 트리의 최대 깊이를 제한하는 파라미터- Random Forest의 ‘랜덤성’을 결정하는 주요 파라미터
- 값 변화별 효과
- 클수록 → 복잡한 패턴 학습, 과적합 ↑
- 작을수록 → 단순한 모델, 과적합 ↓
max_features : 각 노드에서 분할(Split)을 결정할 때, 전체 피처(Feature) 중 일부만 무작위로 골라서 그 최적의 피처를 찾도록 제한하는 설정- 값 변화별 효과
- 클수록 → 트리이 비슷해짐, 과적합 ↑
- 작을수록 → 트리 다양성 증가, 일반화 ↑ (너무 작으면 성능 ↓)
- Options
int : 사용할 feature 개수를 직접 지정float : 전체 피처 대비 비율로 지정 (예: 0.3이면 전체의 30%)sqrt or auto : 전체 피처 개수가 $M$일 때, $\sqrt{M}$ 개만 사용 (분류 문제에서 권장)log2 : $\log_2(M)$ 개를 사용None : 모든 피처를 다 고려, 이는 Bagging 방식과 동일해지며 무작위성이 줄어듦.
min_samples_split : 노드를 분할하기 위해 필요한 최소 샘플 수- 값 변화별 효과
- 클수록 → 분할 덜함 → 모델 단순 → 과적합 ↓
- 작을수록 → 계속 분할 → 모델 복잡 → 과적합 ↑
- Options
int : 최소 샘플 개수float : 전체 데이터 대비 비율
min_samples_leaf : leaf node(최종 노드)에 있어야 하는 최소 샘플 수- 값 변화별 효과
- 클수록 → leaf가 커짐 → 부드러운 모델 → 과적합 ↓
- 작을수록 → leaf가 작아짐 → 복잡한 모델 → 과적합 ↑
- Options
int : 최소 샘플 개수float : 전체 데이터 대비 비율criterion : 노드 분할 기준 (불순도 측정 방식)gini : 지니 불순도 (기본값, 속도 빠름)entropy : 정보 이득 (gini와 성능 차이는 미미, 계산 비용이 더 높음)bootstrap : 복원 추출(Bootstrap) 사용 여부True : Bagging 방식으로 학습 (기본값)False : 전체 데이터를 그대로 사용 → OOB Score 사용 불가class_weight : 클래스 불균형 데이터에서 소수 클래스에 더 높은 가중치 부여None : 모든 클래스 동일 가중치'balanced' : 클래스 빈도에 반비례하여 자동 계산 → 불균형 데이터에 권장
9-1. 전처리 (짧게)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| import pandas as pd
from sklearn.model_selection import train_test_split
titanic = pd.read_csv('./Data/Titanic.csv')
titanic['FamSize'] = titanic['SibSp'] + titanic['Parch']
use_cols = ['Survived', 'Pclass', 'Sex', 'Age', 'FamSize', 'Fare', 'Embarked']
titanic = titanic[use_cols].dropna(subset=['Age'])
titanic['Age'] = titanic['Age'].astype(int)
titanic = pd.get_dummies(titanic, columns=['Pclass', 'Sex', 'Embarked'], drop_first=True)
y = titanic['Survived']
X = titanic.drop('Survived', axis=1)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=0)
# ⚠️ Random Forest는 트리 기반 → 스케일링 불필요
# StandardScaler 생략
|
Note: Random Forest는 트리 기반이므로 특성 스케일에 영향을 받지 않습니다. StandardScaler가 필요 없습니다.
9-2. 모델 학습
1
2
3
4
5
6
7
8
9
10
11
| rf = RandomForestClassifier(
n_estimators = 200, # 생성할 트리 개수
max_depth = 10, # 각 트리의 최대 깊이
max_features = 'sqrt', # 분할 시 사용할 변수
min_samples_split = 2, # 노드 분할 최소 샘플 수
min_samples_leaf = 1, # Leaf 노드의 최소 샘플 수
random_state = 0, # random seed
n_jobs = -1 # 사용할 CPU 코어 개수 (-1: 전체 사용)
)
rf.fit(X_train, y_train)
print(f"OOB Score: {rf.oob_score_:.4f}")
|
9-3. 평가
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| from sklearn.metrics import (
accuracy_score, confusion_matrix,
classification_report, roc_auc_score
)
pred = rf.predict(X_test)
pred_prob = rf.predict_proba(X_test)[:, 1]
cfx = confusion_matrix(y_test, pred)
sensitivity = cfx[1, 1] / (cfx[1, 0] + cfx[1, 1])
specificity = cfx[0, 0] / (cfx[0, 0] + cfx[0, 1])
roc_auc = roc_auc_score(y_test, pred_prob)
print(f"Accuracy : {accuracy_score(y_test, pred) * 100:.2f}%")
print(f"Sensitivity : {sensitivity * 100:.2f}%")
print(f"Specificity : {specificity * 100:.2f}%")
print(f"ROC AUC : {roc_auc:.4f}")
print()
print(classification_report(y_test, pred, target_names=['Died (0)', 'Survived (1)']))
|
9-4. n_estimators 수렴 확인
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| import matplotlib.pyplot as plt
oob_scores = []
for n in range(10, 301, 10):
rf_tmp = RandomForestClassifier(n_estimators=n, oob_score=True, random_state=0, n_jobs=-1)
rf_tmp.fit(X_train, y_train)
oob_scores.append(rf_tmp.oob_score_)
plt.figure(figsize=(8, 4))
plt.plot(range(10, 301, 10), oob_scores, color='steelblue')
plt.xlabel('n_estimators')
plt.ylabel('OOB Score')
plt.title('Random Forest — n_estimators 수렴 확인')
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
|
OOB Score가 평탄해지는 지점이 충분한 n_estimators입니다.
9-5. 특성 중요도
1
2
3
4
5
6
7
8
9
10
11
12
| import pandas as pd
import matplotlib.pyplot as plt
importances = pd.Series(rf.feature_importances_, index=X.columns)
importances = importances.sort_values(ascending=True)
plt.figure(figsize=(7, 5))
importances.plot(kind='barh', color='steelblue')
plt.xlabel('Feature Importance (Gini 기반 평균)')
plt.title('Random Forest Feature Importance')
plt.tight_layout()
plt.show()
|