1. 왜 등장했는가
대부분의 ML 알고리즘은 학습 단계에서 명시적인 모델(계수, 트리 구조 등)을 만듭니다.
KNN은 반대로 학습을 아예 하지 않고, 예측 시점에 가장 가까운 이웃을 찾아 답을 내는 방식입니다.
모델을 따로 저장하지 않고 데이터 자체를 기억하기 때문에 게으른 학습(Lazy Learning) 이라고 불립니다.
단순하지만 강력한 직관을 담고 있습니다.
“비슷한 것끼리는 비슷한 결과를 낳는다” — 이 하나의 원리로 분류와 회귀를 모두 해결합니다.
2. 핵심 아이디어 — 비슷한 것끼리 같은 답
KNN은 본질적으로 동네를 보고 집값을 가늠하는 것과 같습니다.
1
2
3
4
5
6
7
8
9
10
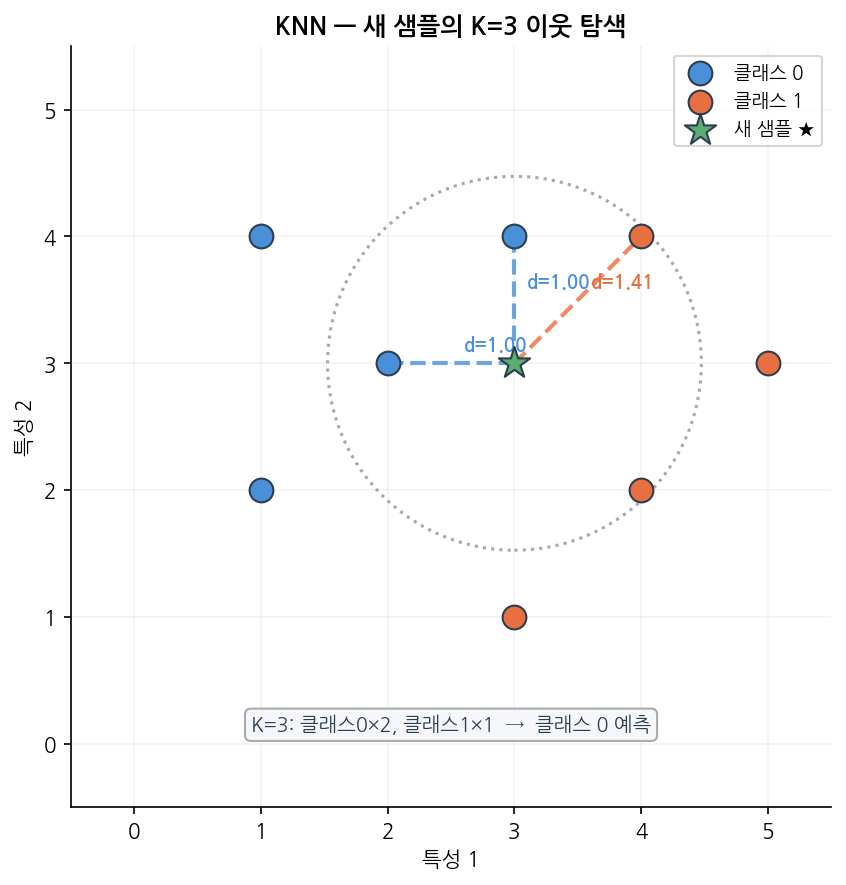
| 새 샘플 ★ 가 들어왔을 때 (K=3):
○ ○
○ ★ ● 가장 가까운 3개 이웃 찾기
○ ● → 이웃 1: ○ (거리 1.2)
● → 이웃 2: ○ (거리 1.5)
→ 이웃 3: ● (거리 2.1)
K=3 이웃: ○ 2개, ● 1개
→ 다수결: ★ = ○ 로 분류
|
K개의 가장 가까운 이웃을 찾아 분류는 다수결, 회귀는 평균으로 예측합니다.
알고리즘은 학습 단계에서 아무것도 계산하지 않고 데이터를 그대로 저장합니다.
3. 실제 예시로 보기 (분류 / 회귀)
예시 1 — 타이타닉 생존 예측 (분류)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| 훈련 데이터 (스케일링 후):
┌────────┬────────┬──────┬──────────┬──────────┐
│ 이름 │ 성별 │ 나이 │ 객실 등급 │ 생존 여부 │
├────────┼────────┼──────┼──────────┼──────────┤
│ Alice │ 0.0 │ -0.5 │ -1.2 │ ✅ │
│ Bob │ 1.0 │ 0.2 │ 0.8 │ ❌ │
│ Carol │ 0.0 │ 1.1 │ 0.8 │ ✅ │
│ Dave │ 1.0 │ -1.5 │ -0.4 │ ✅ │
│ Eve │ 1.0 │ 0.5 │ 0.8 │ ❌ │
└────────┴────────┴──────┴──────────┴──────────┘
새 승객 Frank: 남성(1.0), 나이=0.3, 등급=0.8
유클리드 거리 계산:
Frank → Bob: √((1-1)² + (0.3-0.2)² + (0.8-0.8)²) ≈ 0.10 ★ 가장 가까움
Frank → Eve: √((1-1)² + (0.3-0.5)² ) ≈ 0.20
Frank → Dave: √((1-1)² + (0.3+1.5)² + (0.8+0.4)²) ≈ 2.16
K=3 이웃: Bob(❌), Eve(❌), Carol(✅)
다수결: ❌ 2 vs ✅ 1 → Frank = ❌ 사망 예측
|
예시 2 — 집값 예측 (회귀)
1
2
3
4
| 이웃 3채의 실거래가: 4억, 5억, 4.5억
K=3 이웃의 평균:
(4 + 5 + 4.5) / 3 = 4.5억 예측
|
4. 알고리즘 구성 요소
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| 새 샘플 x 입력
│
▼
┌─────────────────────────────┐
│ 모든 훈련 샘플과 거리 계산 │ ← 유클리드, 맨해튼 등
└─────────────┬───────────────┘
│
▼
┌─────────────────────────────┐
│ 거리 기준 K개 이웃 선택 │ ← 가장 가까운 K개
└─────────────┬───────────────┘
│
┌─────┴─────┐
▼ ▼
[분류] [회귀]
다수결 클래스 이웃 값의 평균
|
| 구성 요소 | 설명 | 비유 |
|---|
| K | 참고할 이웃 수 | 몇 명에게 물어볼지 |
| 거리 함수 | 두 샘플 간의 거리 측정 방법 | 가깝다는 기준 |
| 다수결/평균 | 이웃의 답을 종합하는 방법 | 친구들 의견 모으기 |
| fit() | 데이터 저장만 함 (학습 없음) | 교재를 책상에 올려두기 |
5. 어떻게 거리를 계산하는가
5-1. 유클리드 거리 (기본값)
\[d(a, b) = \sqrt{\sum_{i=1}^{p}(a_i - b_i)^2}\]
1
2
3
| 점 A = (1, 2), 점 B = (4, 6)
d = √((4-1)² + (6-2)²) = √(9 + 16) = √25 = 5
|
두 점 사이의 “직선 거리”를 계산합니다. 일상에서 자로 재는 거리와 동일한 개념입니다.
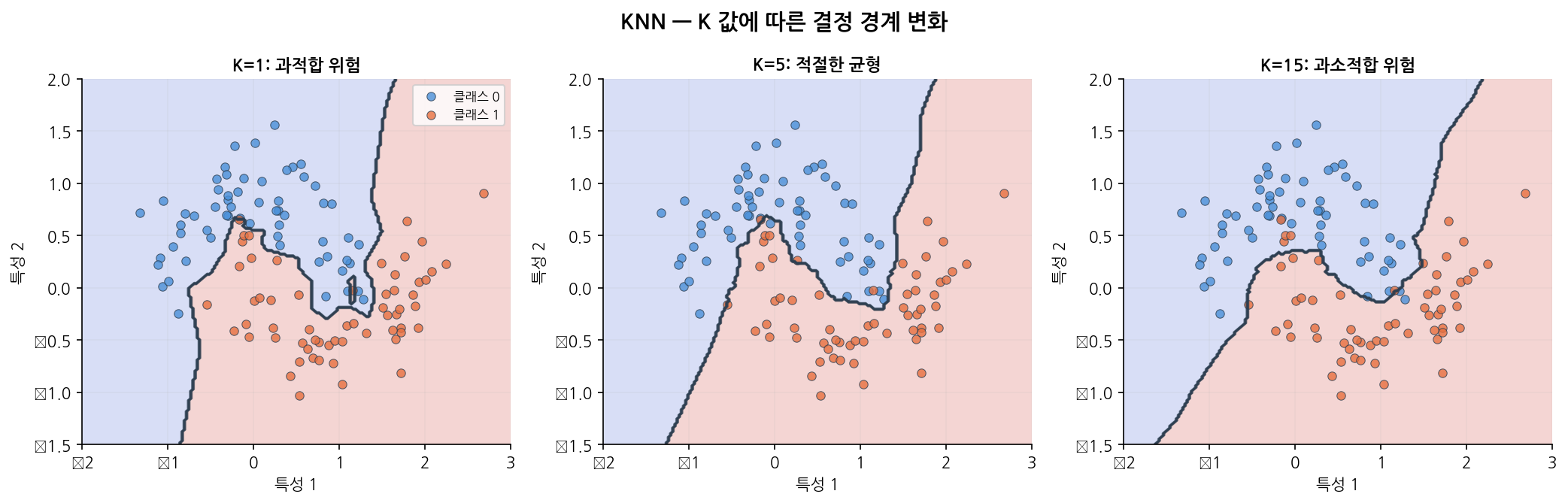
아래 그래프는 다양한 K 값에서 KNN이 어떤 결정 경계를 그리는지 보여줍니다.
읽는 법:
왼쪽 — 유클리드 거리(원형 등고선)와 맨해튼 거리(마름모 등고선)의 차이를 보여줍니다.
오른쪽 — K=1일 때 각 훈련 샘플 주변이 해당 클래스 영역이 되어 가장 복잡한 경계가 생깁니다.
K가 커질수록 경계가 부드러워지고 노이즈에 덜 민감해집니다.
5-2. 맨해튼 거리
\[d(a, b) = \sum_{i=1}^{p}|a_i - b_i|\]
1
2
3
| d = |4-1| + |6-2| = 3 + 4 = 7
격자 도시에서 블록 수로 이동하는 것과 같음
|
5-3. K 값의 영향
1
2
3
4
5
6
7
| K=1: 훈련 데이터 형태 그대로 → 과적합 위험
(노이즈 포인트 하나에도 경계 흔들림)
K=3~5: 실전 권장 시작값. 적절한 균형
K=N: 항상 가장 많은 클래스 예측 → 과소적합
(모든 훈련 샘플을 이웃으로 쓰므로 항상 같은 답)
|
6. KNN 장・단점
6-1. ✅ KNN 장점
1
2
3
4
5
6
7
8
9
10
11
| 1. 학습 과정이 없음
→ fit()이 데이터를 저장만 함 → 즉시 사용 가능
2. 이해하기 쉬움
→ "가까운 이웃을 보고 판단" → 직관적
3. 비선형 경계 자연스럽게 학습
→ 복잡한 패턴도 K를 조정하며 포착 가능
4. 다중 클래스 자연 지원
→ 이진 분류에만 국한되지 않음
|
6-2. ❌ KNN이 약한 상황
1
2
3
4
5
6
7
8
9
10
11
12
| 1. 예측이 느림
→ 매 예측마다 전체 훈련 데이터와 거리 계산 → O(N×p)
→ 데이터 많을수록 급격히 느려짐
2. 고차원 데이터 (차원의 저주)
→ 특성 수 늘어날수록 모든 점이 비슷한 거리 → 거리 의미 없어짐
3. 스케일링 필수
→ 단위 다른 특성이 거리를 왜곡 → 반드시 전처리
4. 결측값 처리 불가
→ 거리 계산 불가 → 반드시 imputation 필요
|
6-2-1. 스케일링 필수 문제
KNN의 가장 중요한 전처리 요구사항입니다.
나이(0~80) vs 연봉(0~100,000,000)이 같이 있을 때:
1
2
3
4
5
6
| 스케일링 없이:
거리 = √((나이차)² + (연봉차)²)
≈ √(0 + (연봉차)²) ← 연봉만 거리를 지배
스케일링 후:
두 특성이 동등하게 거리에 기여
|
K 값에 따른 결정 경계 변화를 시각적으로 확인해보세요.
읽는 법:
왼쪽에서 오른쪽으로 갈수록 K가 커집니다.
K=1은 훈련 데이터 각 포인트에 딱 붙는 매우 복잡한 경계(과적합)이고,
K가 커질수록 경계가 점점 단순해집니다.
테스트 데이터에서 성능이 가장 좋은 K 값이 최적 K입니다.
해결책 :
1
2
3
4
5
| from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train) # 훈련 데이터로 fit + transform
X_test = scaler.transform(X_test) # 테스트 데이터는 transform만
|
7. 한눈에 요약
| 항목 | 내용 |
|---|
| 알고리즘 유형 | 지도학습 / 분류 & 회귀 모두 가능 |
| 핵심 아이디어 | 가장 가까운 K개 이웃의 다수결 또는 평균 |
| 학습 방식 | Lazy Learning (학습 없음, 데이터 저장만) |
| 거리 함수 | 유클리드 (기본), 맨해튼 등 |
| 스케일링 필요? | ✅ 필수 (거리 기반) |
| 핵심 파라미터 | n_neighbors (K), metric |
| 실전 사용 | 소규모 데이터, 추천 시스템, 빠른 프로토타입 |
8. 다른 알고리즘과 무엇이 다른가
Decision Tree vs KNN
1
2
3
4
5
6
| Decision Tree: KNN:
규칙을 학습 → 저장 데이터 자체를 저장
예측: 규칙 따라가기 (빠름) 예측: 거리 계산 (느림)
학습: 느림 학습: 없음 (즉시)
스케일링: 불필요 스케일링: 필수
해석: 트리 구조로 설명 가능 해석: "이웃이 이러니까" 정도만 가능
|
| 항목 | Decision Tree | KNN |
|---|
| 학습 속도 | 느림 | 없음 (즉시) |
| 예측 속도 | 빠름 | 느림 (N 클수록) |
| 스케일링 | ❌ 불필요 | ✅ 필수 |
| 해석 | 트리 시각화 | “이웃이 이러니까” |
| 고차원 | 보통 | ⚠️ 차원의 저주 |
9. 코드로 보기 — 타이타닉 생존 예측
1
2
3
4
5
6
7
8
9
10
11
| from sklearn.neighbors import KNeighborsClassifier
KNN = KNeighborsClassifier(
n_neighbors = 5, # 분류에 사용할 이웃의 개수(k)
weights = 'uniform', # 이웃의 가중치
algorithm = 'auto', # 이웃을 검색
leaf_size = 30, # 리프 노드의 크기
p = 2, # 거리 측정 방법
metric = 'minkowski', # 거리의 평가 지표
n_jobs = -1, # 사용할 CPU 개수
)
|
| Parameter | 설명 | Default |
|---|
n_neighbors | 참조할 이웃 수 (K) | 5 |
weights | 거리 가중치 | uniform |
algorithm | 이웃 탐색 알고리즘 | auto |
metric | 거리 계산 방식 | minkowski |
p | 민코프스키 차수 (1 = 맨해튼, 2 = 유클리드) | 2 |
n_jobs | 병렬 처리 CPU 코어 수 (-1: 전체) | None |
n_neighbors : 참조할 이웃 수 K — 가장 중요한 파라미터- 값 변화별 효과
- 클수록 → 더 많은 이웃 참조 → 경계 부드러움 → 과소적합 ↑
- 작을수록 → 이웃 적음 → 경계 복잡 → 과적합 ↑
- K=1은 최근접 이웃만 참조 → 과적합 위험 가장 높음
- 최적 K는 교차 검증으로 결정 (보통 5~20)
weights : 이웃의 투표 방식- 값 변화별 효과
uniform → 모든 이웃 동일 가중치 (기본값)distance → 가까운 이웃에 높은 가중치 ($w = 1/d$) → 일반적으로 더 좋은 성능
algorithm : 이웃 탐색 내부 알고리즘auto → 입력 데이터에 따라 자동 선택 (기본값)ball_tree → 고차원 데이터에서 효율적kd_tree → 저차원(~ 20개 이하) 데이터에서 빠름brute → 전수 탐색, 소규모 데이터에 적합
metric / p : 거리 측정 방식- 값 변화별 효과
p = 2 (유클리드) → 연속형 변수에 일반적p = 1 (맨해튼) → 이상치에 강건, 격자형 데이터에 적합
⚠️ Caution: KNN 모델에는 random_state 옵션이 없습니다
이유: KNeighborsClassifier 및 KNeighborsRegressor는 무작위성(Randomness)이 없는 100% 결정론적(Deterministic) 알고리즘입니다. 거리를 기반으로 이웃을 찾기 때문에 입력 데이터가 같다면 항상 동일한 결과를 반환하므로 내부 난수 시드가 필요하지 않습니다.
참고: 만약 KNN 실행 시마다 결과가 달라진다면, 모델 자체의 문제가 아니라 앞선 데이터 분할(train_test_split)이나 교차 검증(KFold) 단계에서 random_state가 누락되었는지 확인하시기 바랍니다.
9-1. 전처리
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
titanic = pd.read_csv('./Data/Titanic.csv')
titanic['FamSize'] = titanic['SibSp'] + titanic['Parch']
use_cols = ['Survived', 'Pclass', 'Sex', 'Age', 'FamSize', 'Fare', 'Embarked']
titanic = titanic[use_cols].dropna(subset=['Age'])
titanic['Age'] = titanic['Age'].astype(int)
titanic = pd.get_dummies(titanic, columns=['Pclass', 'Sex', 'Embarked'], drop_first=True)
y = titanic['Survived']
X = titanic.drop('Survived', axis=1)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=0)
# ✅ KNN은 거리 기반 → 스케일링 필수
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
|
Note: KNN은 거리 기반 알고리즘이므로 StandardScaler가 반드시 필요합니다.
fit_transform은 훈련 데이터에만, transform은 테스트 데이터에만 적용합니다.
9-2. 모델 학습
1
2
3
4
5
6
| knn = KNeighborsClassifier(
n_neighbors=5, # K: 참고할 이웃 수
metric='euclidean', # 거리 함수
weights='uniform' # 이웃 가중치: 'uniform'(동등) 또는 'distance'(가까울수록 ↑)
)
knn.fit(X_train, y_train)
|
| Parameter | Default | 역할 | 과적합 방향 |
|---|
n_neighbors | 5 | 이웃 수 K | 작을수록 과적합 ↑ |
metric | 'minkowski' | 거리 함수 | - |
weights | 'uniform' | 이웃 가중치 방식 | - |
algorithm | 'auto' | 거리 계산 알고리즘 | - |
n_neighbors (K) : 가장 중요한 파라미터- 값 변화별 효과
- 작을수록 → 복잡한 경계, 노이즈에 민감, 과적합 ↑
- 클수록 → 부드러운 경계, 과소적합 위험
- 보통 홀수 권장 (동점 방지)
- 최적 K 탐색은 아래 학습 곡선 코드 참고
weights : 거리 가중치'uniform' : 모든 이웃 동등 취급 (기본값)'distance' : 가까운 이웃에 더 큰 가중치 → 성능 개선 가능
metric : 거리 함수'euclidean' : 직선 거리 (기본)'manhattan' : 격자 거리 (이상치에 약간 강함)
9-2-1. 최적 K 탐색
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| import matplotlib.pyplot as plt
from sklearn.metrics import roc_auc_score
k_range = range(1, 31)
train_scores, test_scores = [], []
for k in k_range:
knn_tmp = KNeighborsClassifier(n_neighbors=k)
knn_tmp.fit(X_train, y_train)
train_scores.append(roc_auc_score(y_train, knn_tmp.predict_proba(X_train)[:, 1]))
test_scores.append(roc_auc_score(y_test, knn_tmp.predict_proba(X_test)[:, 1]))
plt.figure(figsize=(8, 4))
plt.plot(k_range, train_scores, label='Train AUC', color='steelblue')
plt.plot(k_range, test_scores, label='Test AUC', color='tomato')
plt.xlabel('K (n_neighbors)')
plt.ylabel('ROC AUC')
plt.title('KNN — K 값에 따른 성능')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
|
9-3. 평가
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| from sklearn.metrics import (
accuracy_score, confusion_matrix,
classification_report, roc_auc_score
)
pred = knn.predict(X_test)
pred_prob = knn.predict_proba(X_test)[:, 1]
cfx = confusion_matrix(y_test, pred)
sensitivity = cfx[1, 1] / (cfx[1, 0] + cfx[1, 1])
specificity = cfx[0, 0] / (cfx[0, 0] + cfx[0, 1])
roc_auc = roc_auc_score(y_test, pred_prob)
print(f"Accuracy : {accuracy_score(y_test, pred) * 100:.2f}%")
print(f"Sensitivity : {sensitivity * 100:.2f}%")
print(f"Specificity : {specificity * 100:.2f}%")
print(f"ROC AUC : {roc_auc:.4f}")
print()
print(classification_report(y_test, pred, target_names=['Died (0)', 'Survived (1)']))
|