[Python] ML-Gradient Boosting
1. 왜 등장했는가
AdaBoost는 틀린 샘플의 가중치를 높이는 방식이었지만, 이상치에 취약한 문제가 있었습니다.
Gradient Boosting은 “잔차(residual)를 직접 다음 모델이 학습” 하는 방식으로 이를 일반화했습니다.
손실 함수의 음의 기울기(Negative Gradient)를 잔차로 보고 트리를 순서대로 쌓아나갑니다. (Friedman, 2001)
AdaBoost가 “틀린 문제에 별표를 치는” 방식이라면,
Gradient Boosting은 “틀린 정도(오차 크기)까지 숫자로 기록해서 그 오차를 직접 배우는” 방식입니다.
2. 핵심 아이디어 — 오차를 다음 트리가 채운다
Gradient Boosting은 본질적으로 이전 모델의 오차를 다음 모델이 보완하는 구조입니다.
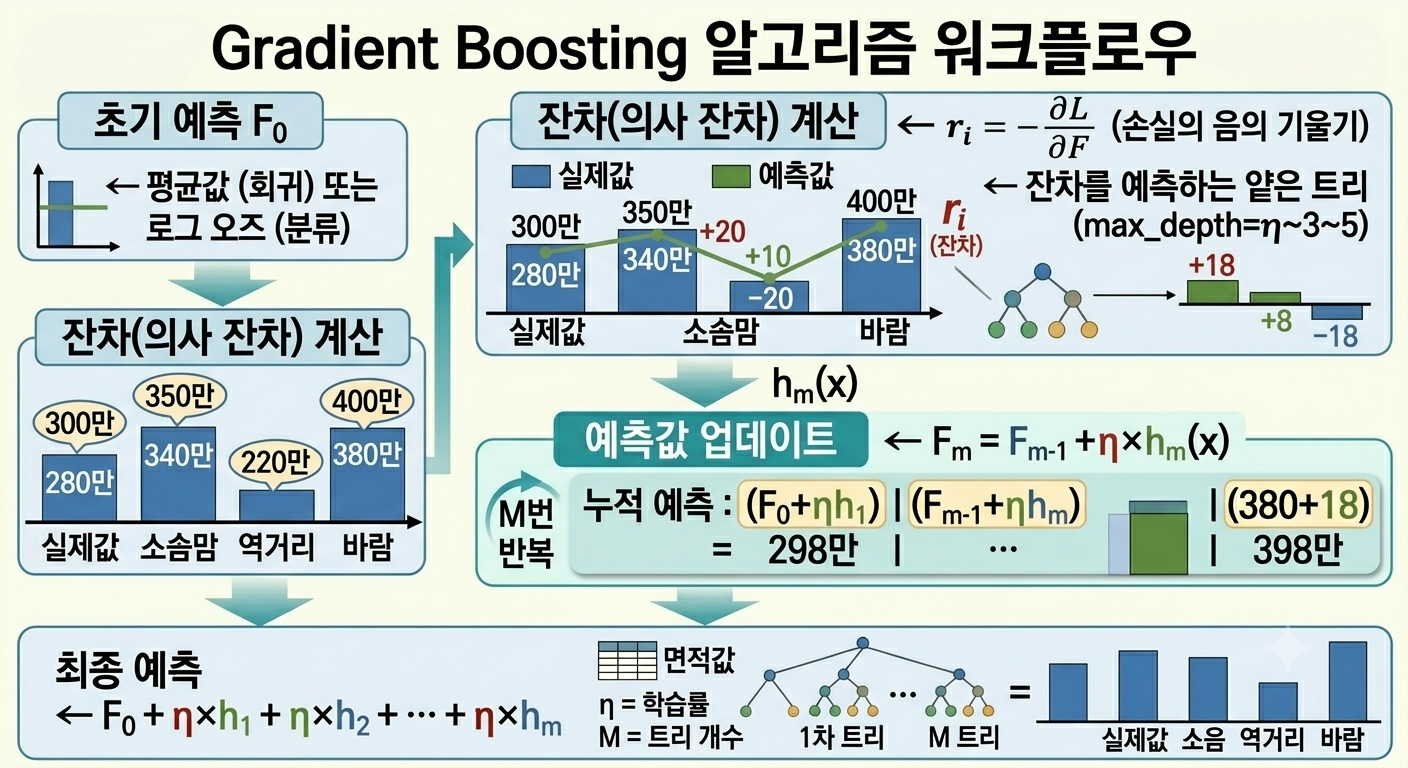
이미지 읽는 방법 (Gradient Boosting 알고리즘 워크플로우)
이 그림은 왼쪽 위 → 오른쪽 위 → 오른쪽 아래 → 왼쪽 아래 순서로 읽으면 됩니다.
잔차(residual)란? 모델이 예측한 값과 실제 값의 차이입니다. 예를 들어 실제 집값이 300만인데 280만으로 예측했다면 잔차는 +20입니다. Gradient Boosting은 이 잔차를 다음 모델이 학습하는 방식으로 점점 정확해집니다.
왼쪽 위 (초기 예측 F₀) — 첫 번째 예측은 단순히 전체 데이터의 평균값(회귀) 또는 로그 오즈(분류)로 시작합니다. 아직 정교하지 않은 기본값입니다.
왼쪽 가운데 (잔차 계산) — 초기 예측값과 실제값의 차이(잔차)를 계산합니다. 실제값(300만, 350만, 220만, 400만)과 예측값(280만, 340만, …)의 차이가 각각 +20, +10, -20으로 표시됩니다.
오른쪽 위 (잔차를 학습하는 트리) — 잔차를 새로운 정답으로 삼아 얕은 트리(max_depth 3~5)를 학습합니다. 이 트리가 +18, +8, -18처럼 잔차를 예측합니다.
오른쪽 가운데 (예측값 업데이트) — 이전 예측값에 η(학습률) × 새 트리 예측값을 더해 업데이트합니다. 예를 들어 280 + 18 = 298만으로 실제값 300만에 더 가까워집니다.
왼쪽 아래 (최종 예측) — 이 과정을 M번 반복한 결과를 모두 더해 최종 예측을 만듭니다. 트리가 많아질수록 실제값에 수렴합니다.
각 트리가 이전까지의 누적 예측이 못 맞춘 부분을 학습합니다.
알고리즘은 학습률(learning_rate)로 각 트리의 기여를 조절합니다.
3. 실제 예시로 보기 (분류 / 회귀)
예시 1 — 타이타닉 생존 예측 (분류)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
훈련 데이터:
┌────────┬────────┬─────┬──────────┬──────────┐
│ 이름 │ 성별 │ 나이 │ 객실 등급 │ 생존 여부 │
├────────┼────────┼─────┼──────────┼──────────┤
│ Alice │ 여성 │ 29 │ 1등석 │ ✅ │
│ Bob │ 남성 │ 31 │ 3등석 │ ❌ │
│ Carol │ 여성 │ 45 │ 3등석 │ ✅ │
│ Dave │ 남성 │ 12 │ 2등석 │ ✅ │
│ Eve │ 남성 │ 38 │ 3등석 │ ❌ │
└────────┴────────┴─────┴──────────┴──────────┘
Step 0: 초기 예측 = 전체 생존율 → P₀ = 0.6
Step 1: 잔차 계산 (실제 - 예측)
Alice: 1 - 0.6 = +0.4
Bob: 0 - 0.6 = -0.6
Carol: 1 - 0.6 = +0.4
Dave: 1 - 0.6 = +0.4
Eve: 0 - 0.6 = -0.6
트리 1 → 이 잔차를 학습 → "Sex=여성 → +0.4, 남성 → -0.6"
Step 2: 예측값 업데이트
P₁ = P₀ + learning_rate × 트리1(x)
Step 3: 새 잔차로 트리 2 학습 → 반복
예시 2 — 집값 예측 (회귀)
1
2
3
4
5
6
실제 집값: 5억 / 초기 예측: 4억 (전체 평균) / 잔차: 1억
트리 1: 면적·위치 반영 → +0.6억 학습 → 누적: 4.06억
트리 2: 층수·향 반영 → +0.3억 학습 → 누적: 4.09억
트리 3: 주변 학군 반영 → +0.2억 학습 → 누적: 4.11억
...100번 반복... → 4.98억 (실제 5억에 수렴)
4. 알고리즘 구성 요소
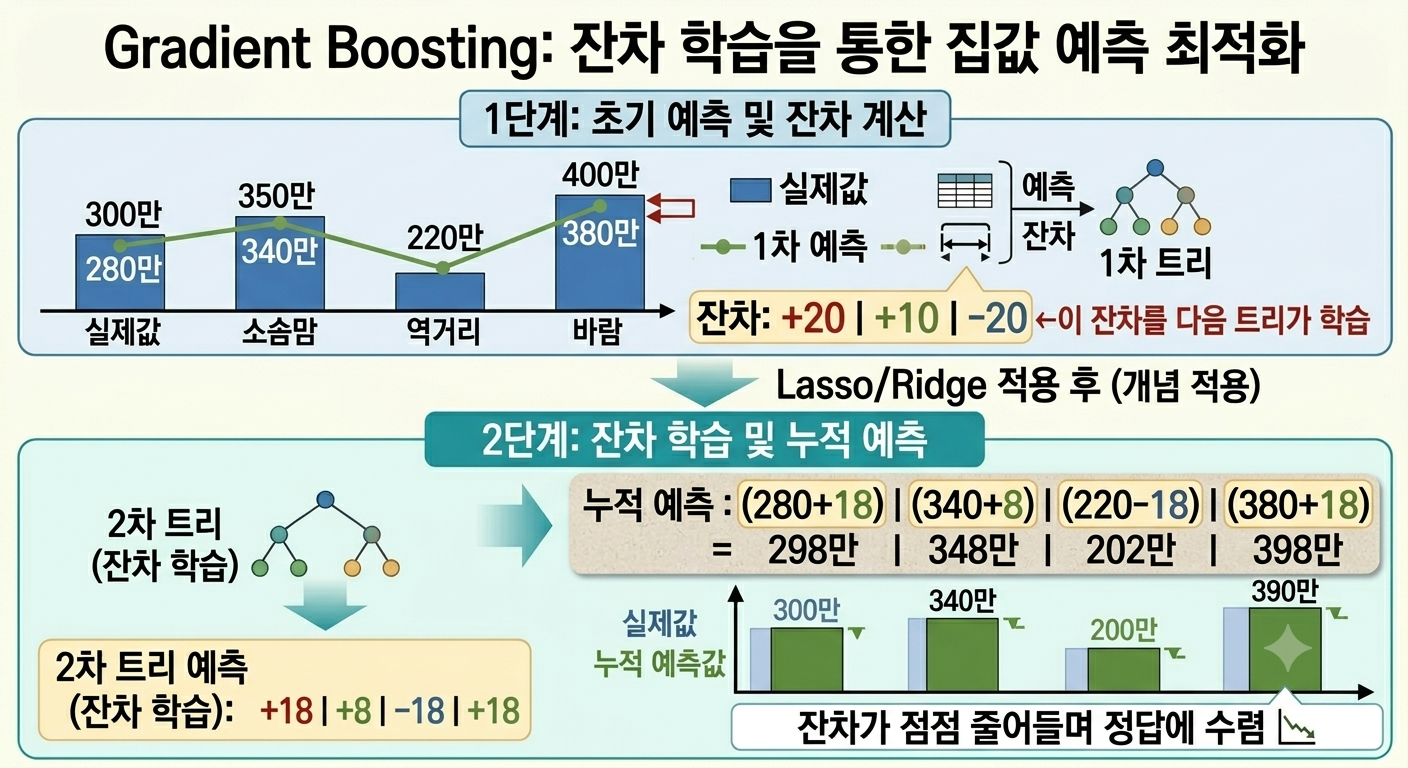
📌 이미지 읽는 방법 (Gradient Boosting 집값 예측 예시)
이 그림은 위(1단계) → 아래(2단계) 순서로 읽으면 됩니다.
위 (1단계: 초기 예측 및 잔차 계산) — 1차 트리가 실제값(300만, 350만, 220만, 400만)을 예측한 결과가 초록 선으로 표시됩니다. 예측이 완벽하지 않아 잔차가 +20, +10, -20으로 남습니다. 이 잔차를 다음 트리가 학습합니다.
가운데 화살표 (Lasso/Ridge 적용) — Gradient Boosting에 Ridge나 Lasso 개념을 함께 적용하면 각 트리의 계수에 패널티를 줘서 과적합을 추가로 방지할 수 있습니다.
아래 왼쪽 (2차 트리) — 1단계의 잔차(+20, +10, -20)를 학습한 2차 트리가 +18, +8, -18, +18을 예측합니다. 완벽하진 않지만 잔차에 더 가까워진 값입니다.
아래 오른쪽 (누적 예측) — 1차 예측에 2차 트리 결과를 더합니다. 280+18=298만, 340+8=348만, 220-18=202만, 380+18=398만으로 실제값(300만, 340만, 200만, 390만)에 훨씬 가까워진 것을 확인할 수 있습니다.
| 구성 요소 | 설명 | 비유 |
|---|---|---|
| F₀ (초기 예측) | 전체 평균 또는 로그 오즈 | 정보 없을 때 기본 답 |
| 잔차 (의사 잔차) | 손실 함수의 음의 기울기 | 현재 모델의 부족한 부분 |
| 트리 hₘ | 잔차를 학습하는 얕은 트리 | 부족한 부분 채우는 선생님 |
| η (learning_rate) | 각 트리 기여도 축소 | 한 번에 너무 많이 수정 금지 |
| M (n_estimators) | 트리 개수 | 수업 반복 횟수 |
5. 어떻게 잔차를 학습하는가
5-1. 손실 함수의 음의 기울기 (의사 잔차)
\[r_{im} = -\left[\frac{\partial L(y_i, F(x_i))}{\partial F(x_i)}\right]_{F=F_{m-1}}\]회귀 (MSE 손실):
\[r_i = y_i - F(x_i) \quad \text{(잔차 = 실제값 - 예측값)}\]분류 (Log Loss):
\[r_i = y_i - p_i \quad (p_i = \sigma(F(x_i)))\]아래 그래프는 잔차가 단계별로 어떻게 줄어드는지 시각화한 것입니다.
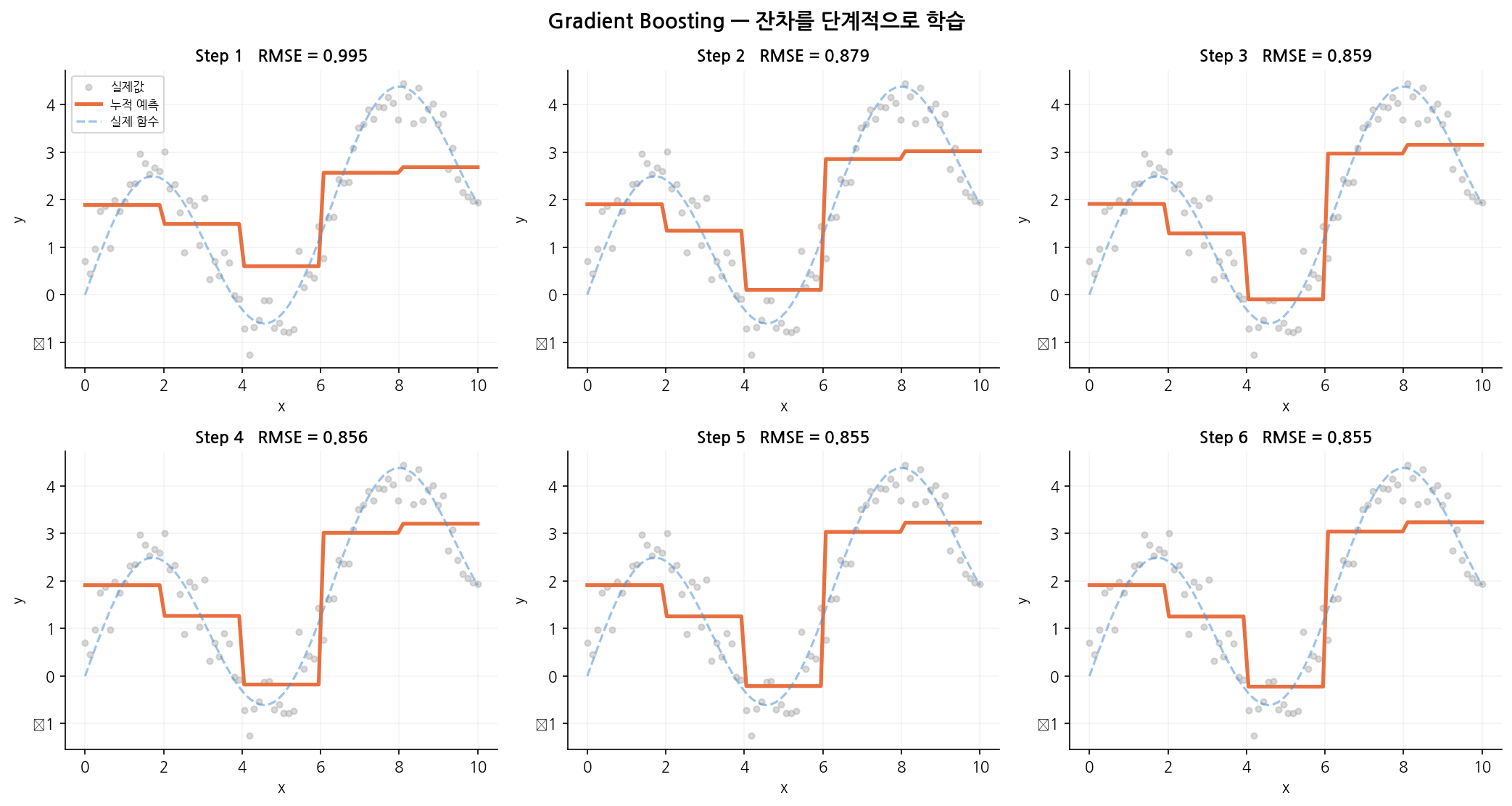
읽는 법:
x축은 트리(라운드) 번호, y축은 잔차의 크기입니다.
초반 트리들이 큰 잔차를 빠르게 줄이고, 후반으로 갈수록 잔차가 작아져 미세 조정에 가까워집니다.
learning_rate가 낮을수록 곡선이 완만하게 내려오고, 높을수록 초반에 급격히 떨어지지만 불안정합니다.
5-2. 예측값 업데이트
\[F_m(x) = F_{m-1}(x) + \eta \cdot h_m(x)\]1
2
3
η = 0.1 (learning_rate)
→ 조금씩 정답에 가까워짐
→ η가 작을수록 안전하지만 트리 더 많이 필요
learning_rate와 n_estimators는 트레이드오프 관계입니다.
learning_rate=0.05로 낮추면 n_estimators=500 정도로 늘려야 비슷한 성능이 나옵니다.
6. Gradient Boosting 장・단점
6-1. ✅ Gradient Boosting 장점
1
2
3
4
5
6
7
8
9
10
11
1. AdaBoost보다 일반적으로 성능 우수
→ 잔차 직접 학습 → 정밀한 오차 감소
2. 다양한 손실 함수 지원
→ MSE, MAE, Log Loss, Huber 등 자유롭게 선택
3. 이상치에 비교적 강함
→ MAE 또는 Huber 손실 사용 시 이상치 영향 감소
4. 특성 중요도 제공
→ 어떤 변수가 중요한지 파악 가능
6-2. ❌ Gradient Boosting이 약한 상황
1
2
3
4
5
6
7
8
1. 학습 속도가 느림
→ 순차 학습 → 병렬화 불가 → LightGBM, XGBoost 권장
2. 하이퍼파라미터가 많음
→ n_estimators, learning_rate, max_depth 동시 조정 필요
3. 대용량 데이터에 비효율
→ sklearn GradientBoosting은 느림 → LightGBM 권장
6-2-1. 과적합 문제
Gradient Boosting의 주요 약점입니다.
n_estimators=1000, learning_rate=1.0일 때:
훈련 손실 → 0에 수렴 ← 훈련 데이터에 과적합
검증 손실 → 일정 이후 증가 ← 새 데이터에서 성능 저하
해결책 :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 방법 1: learning_rate 낮추고 n_estimators 늘리기
gb = GradientBoostingClassifier(learning_rate=0.05, n_estimators=500, random_state=0)
# 방법 2: max_depth 제한
gb = GradientBoostingClassifier(max_depth=3, n_estimators=200, random_state=0)
# 방법 3: subsample로 확률적 GB (과적합 방지)
gb = GradientBoostingClassifier(subsample=0.8, n_estimators=200, random_state=0)
# 방법 4: GridSearchCV로 최적값 탐색
from sklearn.model_selection import GridSearchCV
param_grid = {
'n_estimators': [100, 200, 300],
'learning_rate': [0.01, 0.05, 0.1],
'max_depth': [3, 4, 5],
'subsample': [0.8, 1.0]
}
gb_cv = GridSearchCV(
GradientBoostingClassifier(random_state=0),
param_grid,
cv=5,
scoring='roc_auc'
)
gb_cv.fit(X_train, y_train)
print(f"Best params : {gb_cv.best_params_}")
print(f"Best AUC : {gb_cv.best_score_:.4f}")
7. 한눈에 요약
| 항목 | 내용 |
|---|---|
| 알고리즘 유형 | 지도학습 / 분류 & 회귀 모두 가능 |
| 핵심 아이디어 | 잔차를 다음 트리가 학습 → 오차 점진적 감소 |
| 기반 모델 | 얕은 Decision Tree (보통 max_depth=3~5) |
| 최종 예측 | F₀ + η×h₁ + η×h₂ + … + η×hₘ |
| 스케일링 필요? | ❌ 불필요 |
| 이상치 | ▲ 보통 (MAE/Huber 손실 사용 시 강해짐) |
| 핵심 파라미터 | n_estimators, learning_rate, max_depth |
| 실전 사용 | 정확도 중요한 분류/회귀, XGBoost·LightGBM의 기반 이해 |
8. 다른 알고리즘과 무엇이 다른가
AdaBoost vs Gradient Boosting
1
2
3
4
AdaBoost: Gradient Boosting:
틀린 샘플의 가중치 ↑ 잔차(오차)를 직접 학습
가중치 조정으로 다음 모델 유도 손실 함수 기울기로 방향 결정
이상치에 취약 손실 함수 선택으로 이상치 제어 가능
| 항목 | AdaBoost | Gradient Boosting |
|---|---|---|
| 오차 처리 | 샘플 가중치 조정 | 잔차 직접 학습 |
| 손실 함수 | 지수 손실 고정 | 자유롭게 선택 |
| 이상치 | ⚠️ 매우 취약 | ▲ 비교적 강함 |
| 속도 | 빠름 | 느림 (LightGBM 권장) |
두 알고리즘의 학습 과정 차이를 아래 그래프에서 확인할 수 있습니다.
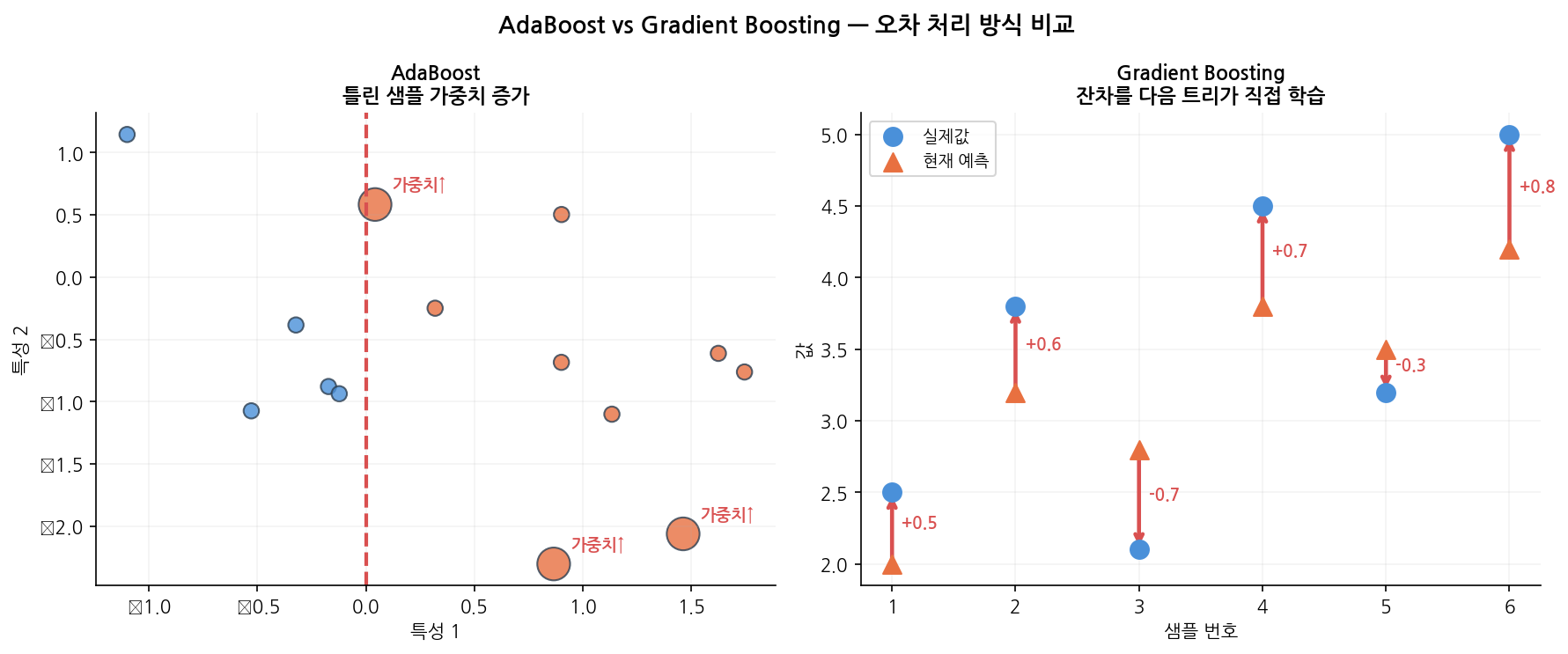
읽는 법:
왼쪽(AdaBoost): 가중치 크기가 이상치 샘플에 집중될수록 성능이 불안정해집니다.
오른쪽(Gradient Boosting): 잔차가 단계적으로 줄어들며 안정적으로 수렴합니다.
깨끗한 데이터라면 두 알고리즘 성능 차이가 크지 않지만, 이상치가 있을 때 Gradient Boosting이 훨씬 안정적입니다.
9. 코드로 보기 — 타이타닉 생존 예측
1
2
3
4
5
6
7
8
9
10
from sklearn.ensemble import GradientBoostingClassifier
gb = GradientBoostingClassifier(
n_estimators = 200, # 트리 수
learning_rate = 0.05, # 각 트리 기여도 (작을수록 안전, n_estimators 늘려야)
max_depth = 3, # 개별 트리 깊이 (보통 3~5 권장)
subsample = 0.8, # 각 트리 학습에 사용할 샘플 비율
random_state = 0
)
| Parameter | Default | 역할 | 과적합 방향 |
|---|---|---|---|
n_estimators | 100 | 트리 수 | 클수록 과적합 ↑ |
learning_rate | 0.1 | 트리 기여도 축소 | 클수록 과적합 ↑ |
max_depth | 3 | 개별 트리 깊이 | 클수록 과적합 ↑ |
subsample | 1.0 | 행 샘플링 비율 | 작을수록 과적합 ↓ |
min_samples_leaf | 1 | 리프 최소 샘플 수 | 작을수록 과적합 ↑ |
n_estimators: 트리를 몇 개 쌓을지- 값 변화별 효과
- 클수록 → 더 정교한 학습, 과적합 ↑
- 작을수록 → 빠른 학습, 과소적합 위험
- 값 변화별 효과
learning_rate: 각 트리의 기여도 축소 계수- 값 변화별 효과
- 작을수록 → 보수적 학습,
n_estimators늘려야 함 - 클수록 → 빠른 수렴, 과적합 위험
- 작을수록 → 보수적 학습,
- 실무 권장:
learning_rate=0.05,n_estimators=300~500
- 값 변화별 효과
max_depth: 개별 트리의 최대 깊이- 값 변화별 효과
- 클수록 → 복잡한 상호작용 학습, 과적합 ↑
- 보통 3~5 사이를 권장
- 값 변화별 효과
subsample: 각 트리 학습에 사용할 샘플 비율- 1.0 미만으로 설정하면 확률적 Gradient Boosting
- 0.8 권장 → 과적합 방지 + 약간의 속도 향상
9-1. 전처리 (짧게)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import pandas as pd
from sklearn.model_selection import train_test_split
titanic = pd.read_csv('./Data/Titanic.csv')
titanic['FamSize'] = titanic['SibSp'] + titanic['Parch']
use_cols = ['Survived', 'Pclass', 'Sex', 'Age', 'FamSize', 'Fare', 'Embarked']
titanic = titanic[use_cols].dropna(subset=['Age'])
titanic['Age'] = titanic['Age'].astype(int)
titanic = pd.get_dummies(titanic, columns=['Pclass', 'Sex', 'Embarked'], drop_first=True)
y = titanic['Survived']
X = titanic.drop('Survived', axis=1)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=0)
# ⚠️ Gradient Boosting은 트리 기반 → 스케일링 불필요
# StandardScaler 생략
Note: Gradient Boosting은 트리 기반이므로 특성 스케일에 영향을 받지 않습니다.
StandardScaler가 필요 없습니다.
9-2. 모델 학습
1
2
3
4
5
6
7
8
gb = GradientBoostingClassifier(
n_estimators=200, # 트리 수
learning_rate=0.05, # 각 트리 기여도 (작을수록 안전, n_estimators 늘려야)
max_depth=3, # 개별 트리 깊이 (보통 3~5 권장)
subsample=0.8, # 각 트리 학습에 사용할 샘플 비율
random_state=0
)
gb.fit(X_train, y_train)
9-3. 평가
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
from sklearn.metrics import (
accuracy_score, confusion_matrix,
classification_report, roc_auc_score
)
pred = gb.predict(X_test)
pred_prob = gb.predict_proba(X_test)[:, 1]
cfx = confusion_matrix(y_test, pred)
sensitivity = cfx[1, 1] / (cfx[1, 0] + cfx[1, 1])
specificity = cfx[0, 0] / (cfx[0, 0] + cfx[0, 1])
roc_auc = roc_auc_score(y_test, pred_prob)
print(f"Accuracy : {accuracy_score(y_test, pred) * 100:.2f}%")
print(f"Sensitivity : {sensitivity * 100:.2f}%")
print(f"Specificity : {specificity * 100:.2f}%")
print(f"ROC AUC : {roc_auc:.4f}")
print()
print(classification_report(y_test, pred, target_names=['Died (0)', 'Survived (1)']))
9-4. 손실 곡선 — staged_predict_proba로 학습 과정 확인
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import matplotlib.pyplot as plt
val_aucs = [
roc_auc_score(y_test, pred[:, 1])
for pred in gb.staged_predict_proba(X_test)
]
plt.figure(figsize=(8, 4))
plt.plot(val_aucs, color='tomato', label='Validation AUC')
plt.xlabel('n_estimators')
plt.ylabel('ROC AUC')
plt.title('Gradient Boosting — 학습 곡선')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
9-5. 특성 중요도
1
2
3
4
5
6
7
8
9
10
11
12
import pandas as pd
import matplotlib.pyplot as plt
importances = pd.Series(gb.feature_importances_, index=X.columns)
importances = importances.sort_values(ascending=True)
plt.figure(figsize=(7, 5))
importances.plot(kind='barh', color='steelblue')
plt.xlabel('Feature Importance')
plt.title('Gradient Boosting Feature Importance')
plt.tight_layout()
plt.show()