[Python] ML-Lasso
1. 왜 등장했는가
선형 회귀는 특성이 많아질수록 계수가 커져 과적합이 생깁니다.
Ridge는 계수를 작게 만들어 이를 완화하지만, 불필요한 특성을 완전히 제거하지는 못합니다.
Lasso는 불필요한 특성의 계수를 정확히 0으로 만들어 모델링과 특성 선택을 동시에 수행합니다. (Tibshirani, 1996)
Ridge가 “모든 특성의 계수를 조금씩 줄이는” 방식이라면,
Lasso는 “중요하지 않은 특성은 아예 무시하고 중요한 특성만 남기는” 방식입니다.
2. 핵심 아이디어 — 계수를 0으로 잘라내기
Lasso는 본질적으로 쓸모없는 특성을 자동으로 제거하는 선형 모델입니다.
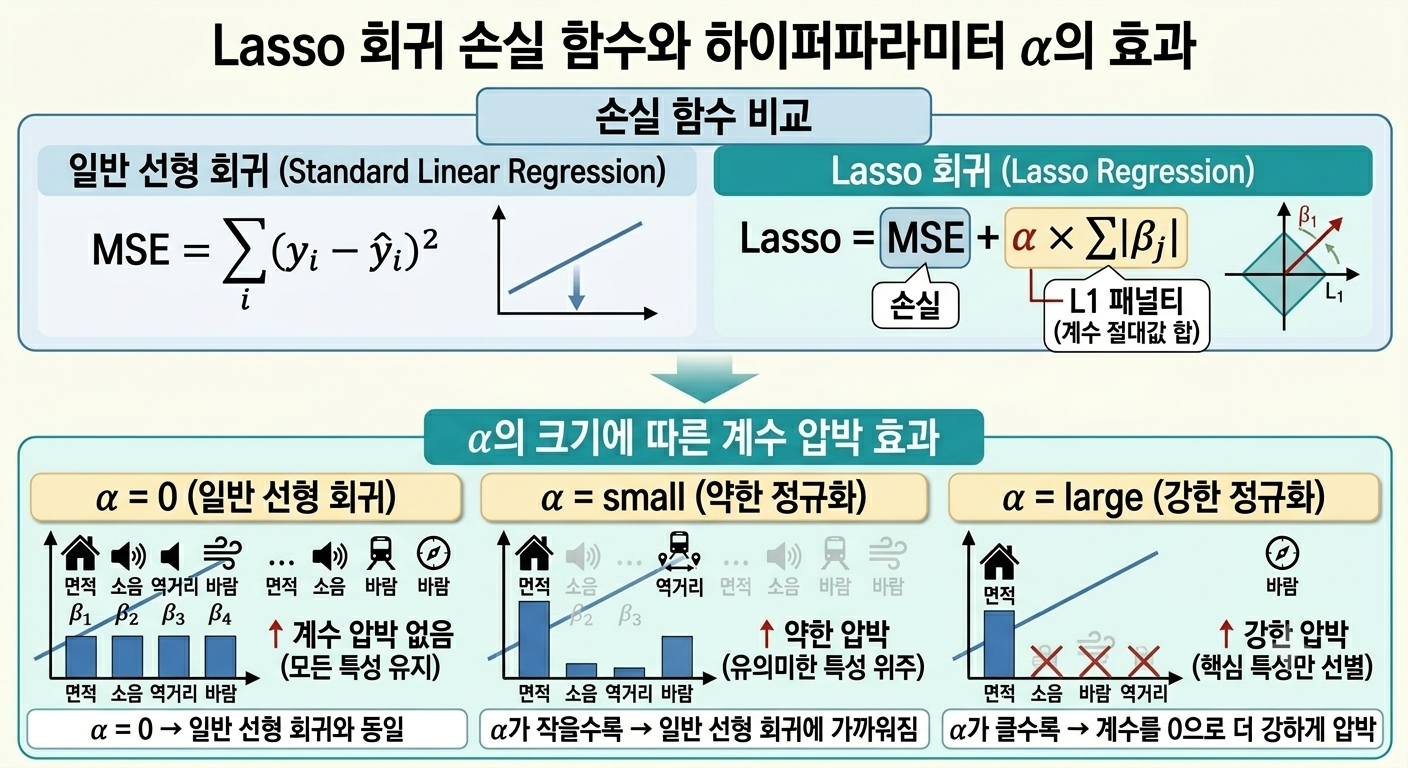
이미지 읽는 방법 (Lasso 손실 함수와 α 효과)
이 그림은 위 → 아래 순서로 읽으면 됩니다.
L1 패널티란? Ridge가 계수를 제곱해서 더했다면, Lasso는 계수의 절대값을 더합니다. 이 차이가 Lasso만의 특징인 “계수를 완전히 0으로 만드는 힘”을 만들어냅니다.
위 (손실 함수 비교) — 일반 회귀는 MSE만 줄이고, Lasso는 MSE + α × Σ|β|를 줄입니다. 오른쪽 마름모 그림은 L1 패널티의 수학적 모양으로, 꼭짓점이 축 위에 있어서 계수가 정확히 0이 되기 쉬운 구조임을 나타냅니다.
아래 왼쪽 (α = 0) — 패널티가 없으므로 면적, 소음, 역거리, 바람 모든 특성의 계수가 살아있습니다. 일반 선형 회귀와 동일합니다.
아래 가운데 (α = small) — 약한 압박으로 중요하지 않은 특성(소음, 바람)의 계수가 작아지기 시작합니다. 유의미한 특성 위주로 정리되는 단계입니다.
아래 오른쪽 (α = large) — 강한 압박으로 소음, 바람, 역거리의 계수가 정확히 0이 되어 사라집니다. 면적과 바람만 살아남아 모델이 핵심 특성만 사용합니다.
💡 Ridge와의 핵심 차이 : Ridge는 계수를 0에 가깝게 줄이지만, Lasso는 계수를 완전히 0으로 만들어 불필요한 변수를 아예 제거합니다. 불필요한 특성의 계수가 정확히 0이 되는 것이 Ridge와의 결정적 차이입니다.
3. 실제 예시로 보기 (회귀 / 분류)
예시 1 — 집값 예측 (회귀)
1
2
3
4
5
6
7
8
9
10
11
12
13
특성 10개: 면적, 층수, 역거리, 소음, 바람, 습도, 주차, 조망, 학군, 연식
일반 선형 회귀 계수:
면적: 2.10 / 층수: 0.85 / 역거리: 1.70
소음: 0.04 ← 작지만 0은 아님
바람: 0.02 ← 작지만 0은 아님
Lasso (alpha=0.1) 계수:
면적: 1.95 / 층수: 0.78 / 역거리: 1.62
소음: 0.00 ← 정확히 0으로 제거
바람: 0.00 ← 정확히 0으로 제거
→ 중요한 특성 3개만 남김 = 자동 특성 선택
예시 2 — 스팸 메일 분류 (분류)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
특성 10개: "광고", "무료", "클릭", "지금", "할인",
"안녕", "첨부", "확인", "링크", "이벤트"
일반 로지스틱 회귀 계수:
광고: 0.85 / 무료: 0.80 / 클릭: 0.78
안녕: 0.03 ← 작지만 0은 아님
첨부: 0.02 ← 작지만 0은 아님
Lasso (alpha=0.1) 계수:
광고: 0.76 / 무료: 0.71 / 클릭: 0.69
안녕: 0.00 ← 정확히 0으로 제거 (스팸과 무관)
첨부: 0.00 ← 정확히 0으로 제거 (스팸과 무관)
→ 스팸과 관련 있는 단어만 자동으로 선별
특성 수가 샘플 수보다 훨씬 많은 상황에서 Lasso가 진가를 발휘합니다.
4. 알고리즘 구성 요소
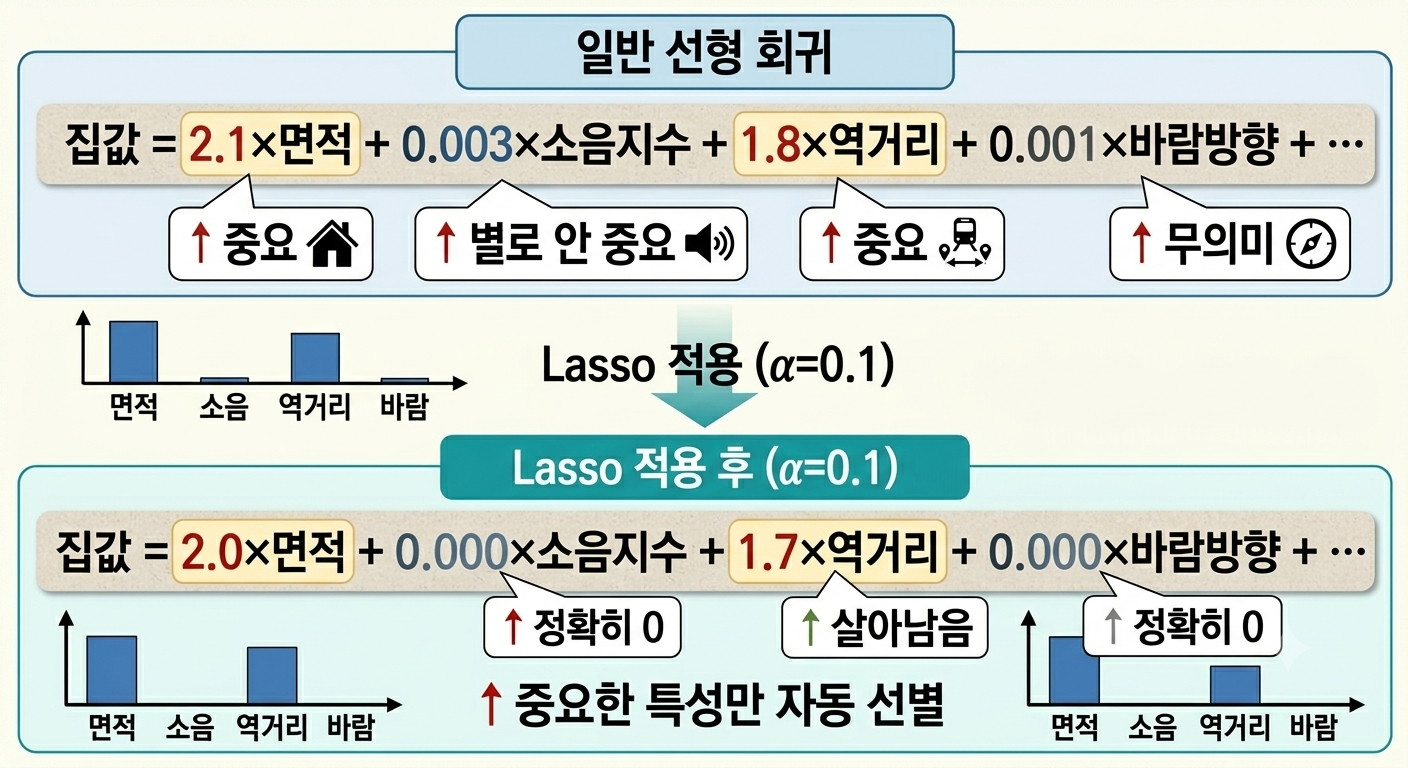
이미지 읽는 방법 (Lasso 적용 전후 비교)
이 그림은 위 → 아래 순서로 읽으면 됩니다.
위 (일반 선형 회귀) — 면적(2.1), 소음(0.003), 역거리(1.8), 바람(0.001) 4개의 계수가 모두 살아있습니다. 소음과 바람은 계수가 매우 작아 사실상 집값에 영향이 없지만, 모델은 이를 구분하지 못하고 모두 포함합니다.
가운데 막대 그래프 — Lasso 적용 전 계수의 크기를 시각화한 것입니다. 면적과 역거리는 막대가 크고, 소음과 바람은 거의 보이지 않을 만큼 작습니다.
아래 (Lasso 적용 후, α=0.1) — 소음(0.000)과 바람(0.000)의 계수가 정확히 0이 됩니다. 면적(2.0)과 역거리(1.7)만 살아남아 모델이 스스로 중요한 특성 2개만 선택한 결과입니다.
| 구성 요소 | 설명 | 비유 |
|---|---|---|
| MSE | 예측 오차 최소화 | 정답에 가깝게 |
| L1 패널티 (Σ|β|) | 계수 절댓값 합 최소화 | 불필요한 특성 잘라내기 |
| α (알파) | 정규화 강도 | 얼마나 많이 잘라낼지 |
5. 어떻게 계수가 0이 되는가
5-1. L1 vs L2 기하학적 이해
1
2
3
4
5
6
7
8
9
10
β₂ β₂
│ ●(MSE 최솟값) │ ●(MSE 최솟값)
│ / │ /
│/ │/
────────●──────── β₁ ────────◆──────── β₁
╱│ │╲
╱ │ │ ╲
L2 (원형 제약) L1 (마름모 제약)
→ 원 위에서 만남 → 꼭짓점(축 위)에서 꼭 만남
→ 계수 ≒ 0 (정확히 0은 아님) → 계수 = 0 자주 발생
L1 패널티의 마름모 꼭짓점이 축 위에 있어, 최솟값이 그 꼭짓점에서 찾아집니다.
꼭짓점은 어느 한 축 좌표가 0인 지점이므로 계수가 정확히 0이 됩니다.
아래 그래프는 L1 (Lasso)과 L2 (Ridge) 패널티의 기하학적 차이를 시각화한 것입니다.
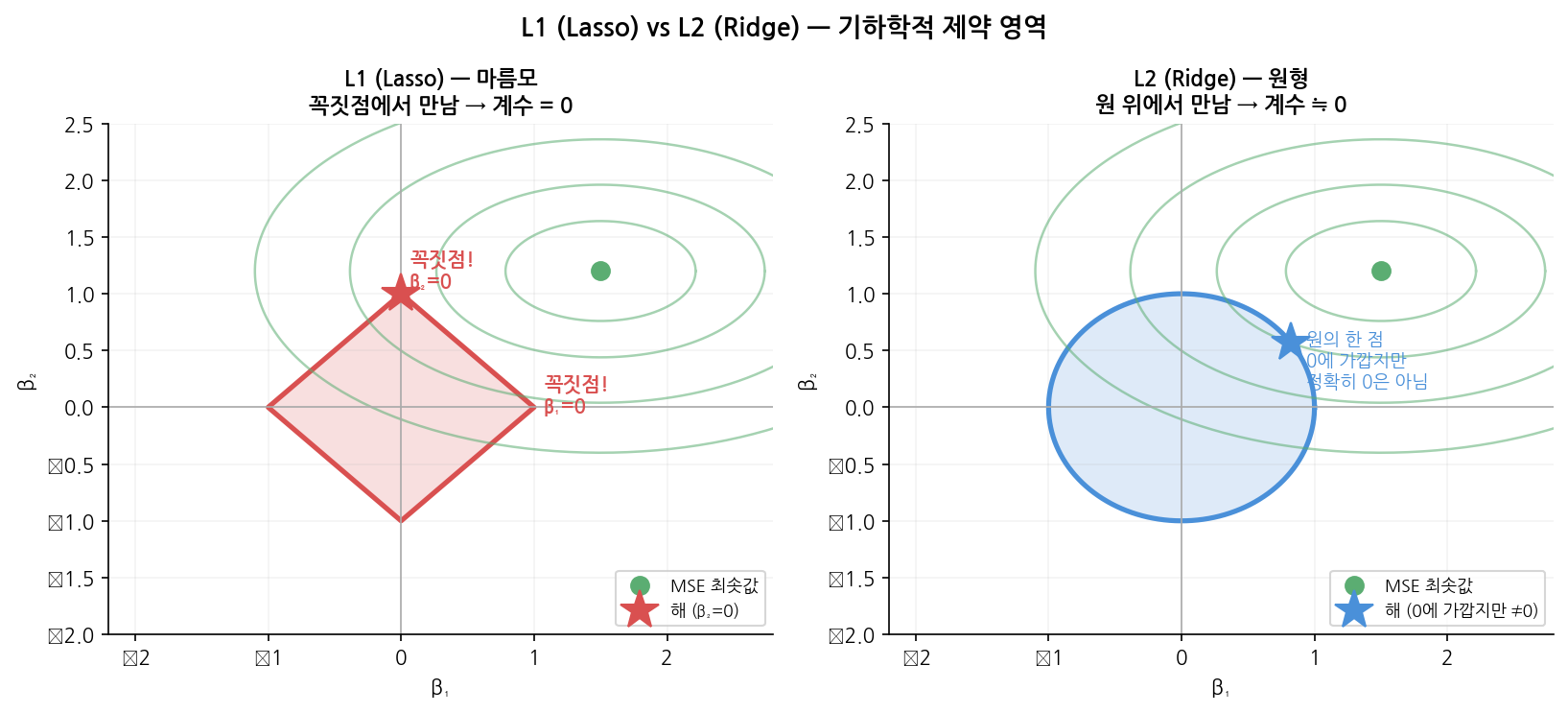
읽는 법:
왼쪽(L2/Ridge): 타원형 등고선이 원형 제약과 만나는 점은 주로 축 위가 아닙니다 → 계수가 0에 가깝지만 정확히 0은 아닙니다.
오른쪽(L1/Lasso): 마름모형 제약의 꼭짓점이 축 위에 있어 타원 등고선과 꼭짓점에서 만날 가능성이 높습니다 → 계수가 정확히 0이 됩니다.
이것이 Lasso가 자동 특성 선택을 수행하는 수학적 이유입니다.
5-2. α 값에 따른 계수 변화
1
2
3
4
5
6
7
α 증가 →
면적 계수: 2.1 → 1.9 → 1.5 → 0.8 → 0.0 (천천히 줄다가 0)
소음 계수: 0.04 → 0.01 → 0.0 (빠르게 0으로)
바람 계수: 0.02 → 0.0 (가장 먼저 0으로)
중요하지 않은 특성일수록 α가 작을 때 먼저 0이 됨
6. Lasso 장・단점
6-1. ✅ Lasso 장점
1
2
3
4
5
6
7
8
9
10
11
1. 자동 특성 선택
→ 불필요한 특성 계수를 정확히 0으로 → 별도 특성 선택 단계 불필요
2. 해석 가능성
→ 살아남은 특성만으로 간결한 모델
3. 고차원 데이터에 강함
→ 특성 수 >> 샘플 수 상황에서도 안정적
4. 과적합 방지
→ 정규화로 계수 크기 제어
6-2. ❌ Lasso가 약한 상황
1
2
3
4
5
6
7
8
9
1. 서로 상관된 특성이 있을 때
→ 비슷한 특성 중 하나만 선택, 나머지는 0으로 → 정보 손실
→ Ridge 또는 ElasticNet 고려
2. 비선형 관계
→ 선형 모델의 한계 → 트리 기반 모델 고려
3. 분류 문제
→ Lasso는 회귀 전용 (분류엔 Logistic Regression + penalty='l1')
6-2-1. 상관 특성 문제
Lasso의 가장 큰 약점입니다.
면적과 방 수가 높은 상관관계일 때:
1
2
3
Lasso: 면적 계수 = 1.9, 방 수 계수 = 0.0 (하나만 선택)
Ridge: 면적 계수 = 1.1, 방 수 계수 = 0.8 (둘 다 나눠서 반영)
ElasticNet: 중간 절충안
해결책 :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
from sklearn.linear_model import ElasticNet
# 방법 1: ElasticNet으로 교체
en = ElasticNet(
alpha=0.1,
l1_ratio=0.5 # 0=Ridge, 1=Lasso, 0.5=50:50 혼합
)
# 방법 2: LassoCV로 최적 α 탐색
from sklearn.linear_model import LassoCV
lasso_cv = LassoCV(
alphas=[0.001, 0.01, 0.1, 1.0, 10.0],
cv=5,
random_state=0
)
lasso_cv.fit(X_train, y_train)
print(f"Best alpha : {lasso_cv.alpha_:.4f}")
7. 한눈에 요약
| 항목 | 내용 |
|---|---|
| 알고리즘 유형 | 지도학습 / 회귀 |
| 핵심 아이디어 | MSE + L1 패널티 → 불필요 계수를 정확히 0으로 |
| 특성 선택 | ✅ 자동 특성 선택 |
| 스케일링 필요? | ✅ 필수 |
| Ridge와 차이 | Ridge는 0에 가깝게, Lasso는 정확히 0으로 |
| 핵심 파라미터 | alpha |
| 실전 사용 | 고차원 데이터, 특성 선택이 필요할 때 |
8. 다른 알고리즘과 무엇이 다른가
Ridge vs Lasso vs ElasticNet
1
2
3
4
5
6
손실 함수 비교:
Linear: MSE
Ridge: MSE + α×Σβⱼ² (L2: 원형 제약, 계수 0에 가깝게)
Lasso: MSE + α×Σ|βⱼ| (L1: 마름모 제약, 계수 정확히 0으로)
ElasticNet: MSE + α×(ρ×Σ|βⱼ| + (1-ρ)×Σβⱼ²) (L1+L2 혼합)
| 항목 | Ridge | Lasso | ElasticNet |
|---|---|---|---|
| 계수 = 0 | ❌ 0에 가깝게 | ✅ 정확히 0 | 일부 0 |
| 특성 선택 | ❌ | ✅ | ✅ 부분적 |
| 상관 특성 | ✅ 강함 | ⚠️ 하나만 선택 | ▲ 보통 |
| 파라미터 | alpha | alpha | alpha, l1_ratio |
9. 코드로 보기 — 집값 예측 (회귀)
1
2
3
4
5
6
from sklearn.linear_model import Lasso, LassoCV
lasso = Lasso(
alpha = 0.1, # 정규화 강도 (클수록 더 많은 계수가 0)
max_iter = 10000 # 수렴 보장을 위해 충분히 크게 설정
)
| Parameter | Default | 역할 | 과적합 방향 |
|---|---|---|---|
alpha | 1.0 | 정규화 강도 | 작을수록 과적합 ↑ |
max_iter | 1000 | 최대 반복 수 | - |
fit_intercept | True | 절편 포함 여부 | - |
alpha: 가장 중요한 파라미터- 값 변화별 효과
- 클수록 → 더 많은 계수가 0으로, 단순한 모델
- 작을수록 → 일반 선형 회귀에 가까워짐, 과적합 ↑
LassoCV로 교차 검증 최적값 자동 탐색 권장
- 값 변화별 효과
max_iter: 좌표하강법의 최대 반복 수- 수렴 경고 발생 시 10000 이상으로 늘리기
- 값 변화별 효과
- 클수록 → 수렴 확실, 느림
- 작을수록 → 미수렴 위험, 빠름
9-1. 전처리
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import pandas as pd
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
data = fetch_california_housing()
X = pd.DataFrame(data.data, columns=data.feature_names)
y = data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=0)
# ✅ Lasso는 계수 크기를 비교하므로 스케일링 필수
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
Note: Lasso는 계수의 절댓값으로 패널티를 계산하므로
StandardScaler가 반드시 필요합니다.
스케일링 없이는 단위가 큰 특성의 계수가 과도하게 패널티를 받습니다.
9-2. 모델 학습
1
2
3
4
5
lasso = Lasso(
alpha = 0.1, # 정규화 강도 (클수록 더 많은 계수가 0)
max_iter = 10000 # 수렴 보장을 위해 충분히 크게 설정
)
lasso.fit(X_train, y_train)
9-2-1. 교차 검증으로 최적 α 탐색
1
2
3
4
5
6
7
lasso_cv = LassoCV(
alphas=[0.001, 0.01, 0.1, 1.0, 10.0],
cv=5,
random_state=0
)
lasso_cv.fit(X_train, y_train)
print(f"Best alpha : {lasso_cv.alpha_:.4f}")
9-3. 평가
1
2
3
4
5
6
7
8
import numpy as np
from sklearn.metrics import mean_squared_error, r2_score
pred = lasso.predict(X_test)
print(f"R² : {r2_score(y_test, pred):.4f}")
print(f"RMSE: {np.sqrt(mean_squared_error(y_test, pred)):.4f}")
print(f"0인 계수 수: {(lasso.coef_ == 0).sum()}개 / 전체 {len(lasso.coef_)}개")
9-4. 계수 시각화 — 어떤 특성이 살아남았는가
1
2
3
4
5
6
7
8
9
10
11
12
import matplotlib.pyplot as plt
coef = pd.Series(lasso.coef_, index=data.feature_names).sort_values()
plt.figure(figsize=(7, 5))
colors = ['tomato' if c > 0 else 'steelblue' for c in coef]
coef.plot(kind='barh', color=colors)
plt.axvline(0, color='black', linewidth=0.8)
plt.xlabel('Coefficient')
plt.title(f'Lasso 계수 (alpha={lasso.alpha})\n0인 특성 수: {(lasso.coef_ == 0).sum()}개')
plt.tight_layout()
plt.show()
9-5. α에 따른 계수 변화 (정규화 경로)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import numpy as np
from sklearn.linear_model import lasso_path
alphas, coefs, _ = lasso_path(X_train, y_train, alphas=np.logspace(-3, 1, 100))
plt.figure(figsize=(8, 5))
for i, name in enumerate(data.feature_names):
plt.semilogx(alphas, coefs[i], label=name)
plt.xlabel('alpha')
plt.ylabel('Coefficient')
plt.title('Lasso 정규화 경로 — α 증가할수록 계수가 0으로')
plt.legend(loc='upper right', fontsize=8)
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
오른쪽으로 갈수록(α 증가) 계수들이 하나씩 0이 되는 것을 확인할 수 있습니다.
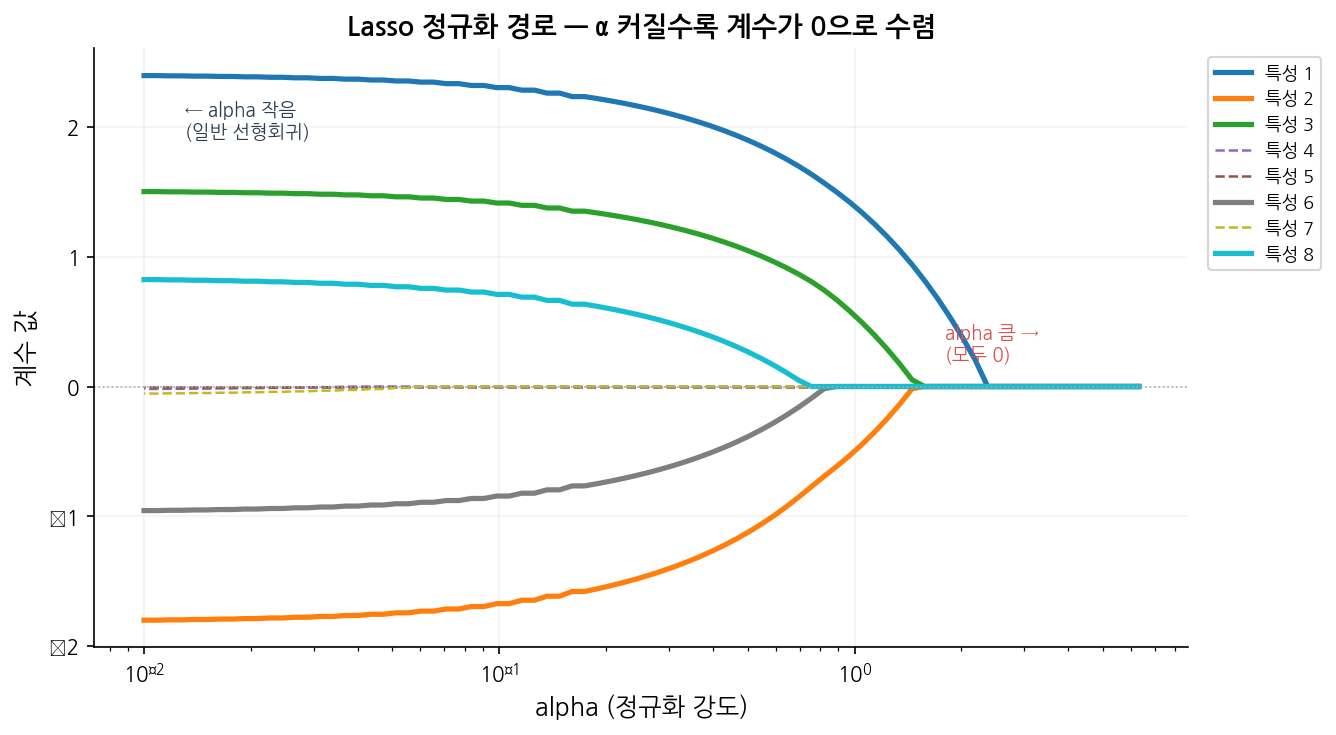
읽는 법:
각 선은 하나의 특성을 나타냅니다.
왼쪽(α 작음)에서는 모든 특성이 계수를 가지며, α가 커질수록 중요도가 낮은 특성부터 차례로 0이 됩니다.
마지막까지 살아남는 특성이 모델에서 가장 중요한 특성입니다.