1. 왜 등장했는가
기존 Gradient Boosting 계열(XGBoost, LightGBM)은 범주형 특성을 직접 처리하지 못해
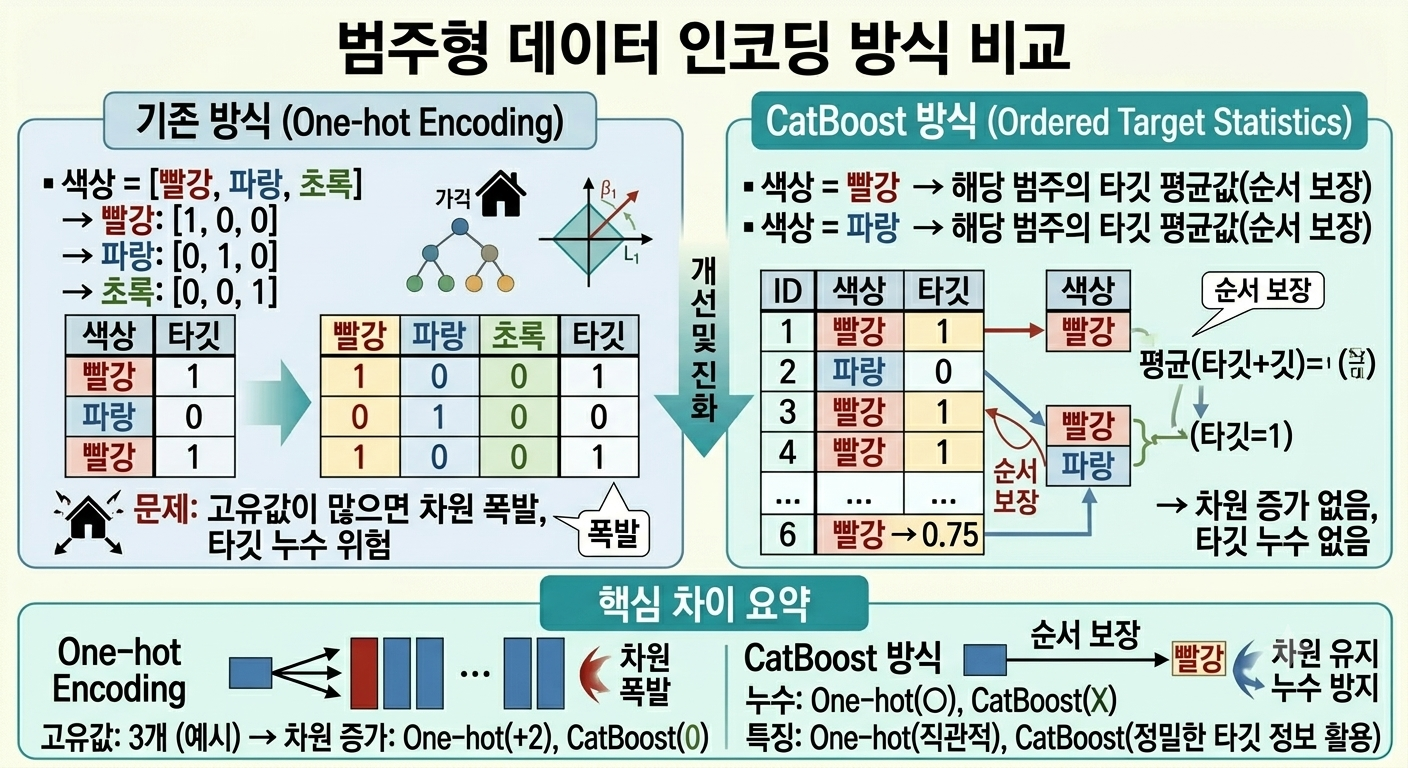
One-hot Encoding 등 별도 전처리가 필요했고, 이 과정에서 타깃 누수(Target Leakage) 문제가 발생했습니다.
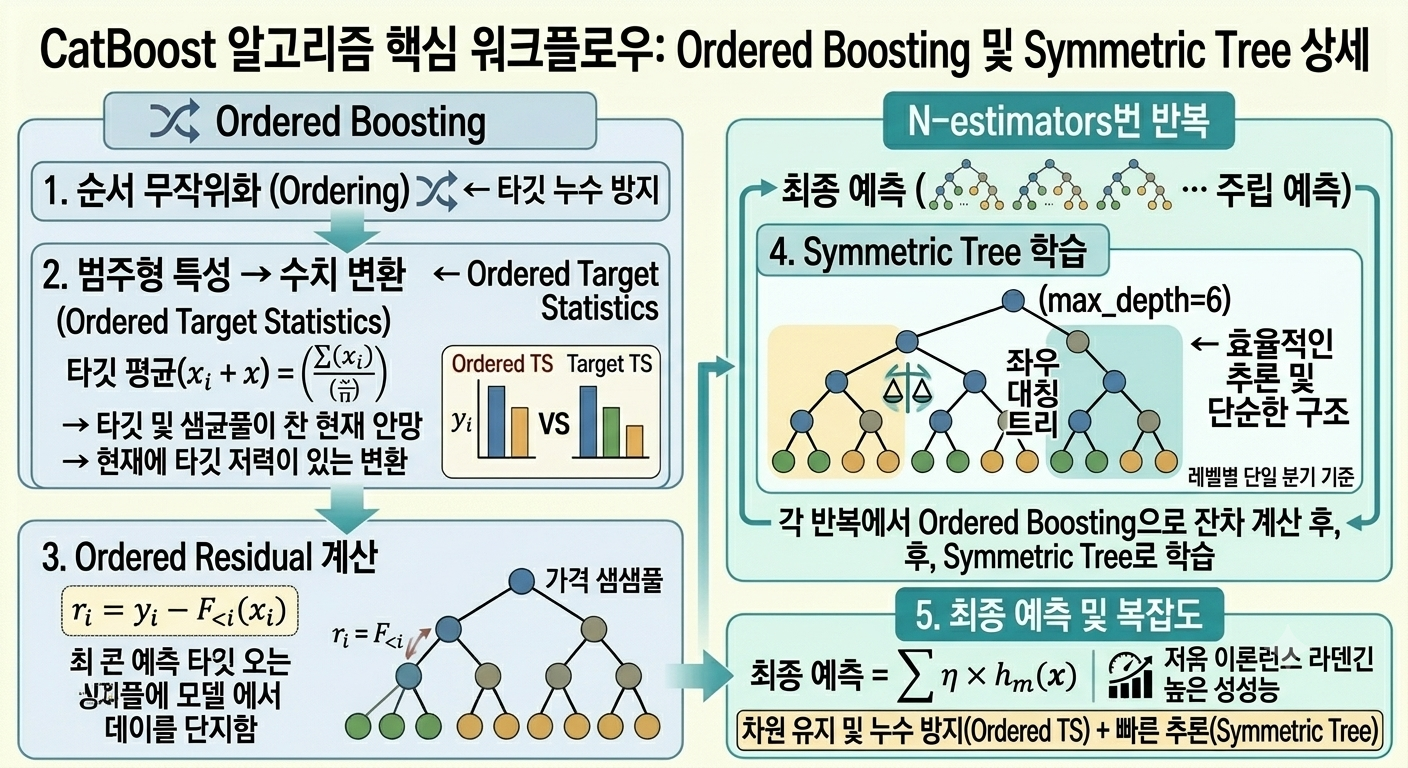
CatBoost는 범주형 특성을 자체적으로 안전하게 처리하고 순서 기반 부스팅으로 편향을 줄인 알고리즘입니다. (Yandex, 2017)
2. 핵심 아이디어 — 범주형 특성을 직접 학습
CatBoost는 본질적으로 범주형 특성에 강한 Gradient Boosting입니다.
각 범주값을 타깃과의 통계적 관계로 수치화하되,
학습 순서를 무작위로 섞어 각 샘플이 자기보다 이전 샘플의 통계만 보도록 합니다.
3. 실제 예시로 보기 (분류 / 회귀)
예시 1 — 타이타닉 생존 예측 (분류)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| 훈련 데이터:
┌────────┬────────┬─────┬──────────┬──────────┐
│ 이름 │ 성별 │ 나이 │ 객실 등급 │ 생존 여부 │
├────────┼────────┼─────┼──────────┼──────────┤
│ Alice │ 여성 │ 29 │ 1등석 │ ✅ │
│ Bob │ 남성 │ 31 │ 3등석 │ ❌ │
│ Carol │ 여성 │ 45 │ 3등석 │ ✅ │
│ Dave │ 남성 │ 12 │ 2등석 │ ✅ │
│ Eve │ 남성 │ 38 │ 3등석 │ ❌ │
└────────┴────────┴─────┴──────────┴──────────┘
기존 방식: Sex 열을 get_dummies()로 변환 필요
Sex_male = [0, 1, 0, 1, 1]
CatBoost 방식: cat_features=['Sex', 'Embarked', 'Pclass'] 지정만 하면 끝
내부적으로 Ordered Target Statistics 계산
→ 전처리 코드 없이 원본 문자열 그대로 사용 가능
|
예시 2 — 상품 추천 (범주형 특성 많은 경우)
1
2
3
4
| 특성: 상품카테고리(100종), 브랜드(500종), 색상(20종), 지역(200종)
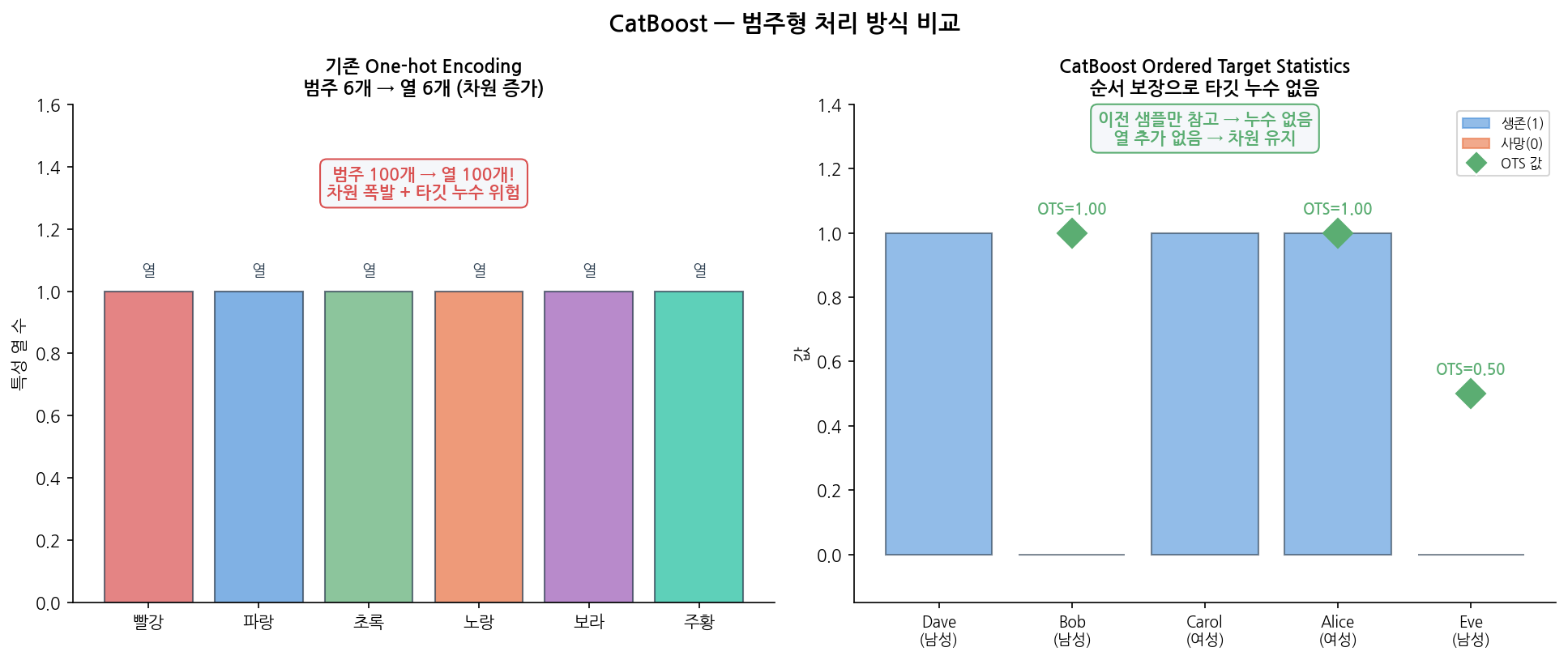
기존 방식: One-hot 후 820개 열 → 차원의 저주
CatBoost: 원본 그대로 입력 → 내부에서 효율적 처리
|
4. 알고리즘 구성 요소
| 구성 요소 | 설명 | 비유 |
|---|
| Ordered Boosting | 학습 순서를 무작위화해 편향 제거 | 시험 답지 순서를 섞어 커닝 방지 |
| Ordered Target Statistics | 범주형 특성을 타깃 통계로 안전하게 수치화 | 카테고리별 합격률로 수치화 |
| Symmetric Tree | 좌우 대칭 구조의 트리 | 균형 잡힌 질문 트리 |
| 내장 범주형 처리 | cat_features 지정만으로 자동 처리 | 번역기 내장 |
5. 어떻게 범주형을 처리하는가
5-1. 기존 방식의 문제 (Target Leakage)
\[\hat{x}_{i,k} = \frac{\sum_{j<i} \mathbf{1}[x_{j,k}=x_{i,k}] \cdot y_j}{\sum_{j<i} \mathbf{1}[x_{j,k}=x_{i,k}]}\]
1
2
3
4
5
6
| 문제: 단순 평균을 쓰면 샘플 자신의 타깃도 통계에 포함
→ 타깃 정보가 특성으로 누출 → 과적합
예시: "성별=여성" 평균 생존율 계산 시
Alice(생존) 본인이 포함된 평균을 Alice 예측에 사용
→ 정답을 미리 알고 맞추는 것과 같음
|
5-2. Ordered Target Statistics (CatBoost 해결책)
1
2
3
4
5
6
7
8
9
10
| 학습 순서를 무작위로 섞은 후:
샘플 순서: Dave → Bob → Carol → Alice → Eve
Dave의 "성별=남성" 통계: (이전 샘플 없음) → prior 사용
Bob의 "성별=남성" 통계: Dave만 참고 → 0/1 = 0.0
Carol의 "성별=여성" 통계: (이전 여성 없음) → prior 사용
Alice의 "성별=여성" 통계: Carol만 참고 → 1/1 = 1.0
→ 각 샘플이 자기 이전 샘플만 보므로 누수 없음
|
6. CatBoost 장・단점
6-1. ✅ CatBoost 장점
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| 1. 범주형 특성 자동 처리
→ get_dummies(), LabelEncoder() 불필요
→ cat_features 파라미터에 열 이름만 넣으면 끝
2. 타깃 누수 없음
→ Ordered Boosting으로 편향 제거
→ 더 신뢰할 수 있는 교차 검증 결과
3. 기본 파라미터로도 좋은 성능
→ 하이퍼파라미터 튜닝 없이도 경쟁력 있는 결과
4. 스케일링 불필요
→ 트리 기반
5. GPU 학습 지원
|
6-2. ❌ CatBoost가 약한 상황
1
2
3
4
5
6
7
8
| 1. 학습 속도
→ Ordered Boosting 연산 비용 → XGBoost/LightGBM보다 느릴 수 있음
2. 범주형 특성이 없는 경우
→ 순수 수치 데이터에서는 LightGBM과 큰 차이 없음
3. 메모리 사용
→ Ordered Boosting을 위해 여러 버전의 모델 유지
|
6-2-1. 범주형 고유값이 매우 많을 때 (High Cardinality)
고유값이 수천 개인 범주형 특성(예: 사용자 ID)은 주의가 필요합니다.
1
2
3
4
5
6
| 사용자 ID: 고유값 100만 개
→ Ordered Target Statistics 계산량 급증
→ 사전에 고빈도 기준으로 그루핑 권장
예시:
userId → 등장 횟수 기준 Top 1000 / 나머지 "기타"
|
해결책 :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| # 방법 1: max_cat_count로 고유값 수 제한
cat = CatBoostClassifier(max_cat_count=100, random_state=0)
# 방법 2: GridSearchCV로 최적값 탐색
from sklearn.model_selection import GridSearchCV
param_grid = {
'iterations': [100, 200, 300],
'learning_rate':[0.01, 0.05, 0.1],
'depth': [4, 6, 8]
}
cat_cv = GridSearchCV(
CatBoostClassifier(random_state=0, verbose=0),
param_grid,
cv=5,
scoring='roc_auc'
)
cat_cv.fit(X_train, y_train, cat_features=cat_cols)
print(f"Best params : {cat_cv.best_params_}")
print(f"Best AUC : {cat_cv.best_score_:.4f}")
|
7. 한눈에 요약
| 항목 | 내용 |
|---|
| 알고리즘 유형 | 지도학습 / 분류 & 회귀 모두 가능 |
| 핵심 아이디어 | Ordered Boosting + 범주형 자동 처리 |
| 기반 모델 | Symmetric Decision Tree |
| 스케일링 필요? | ❌ 불필요 |
| 범주형 처리 | ✅ 자동 (cat_features 지정) |
| 핵심 파라미터 | iterations, learning_rate, depth |
| 실전 사용 | 범주형 특성 많을 때, 전처리 최소화하고 싶을 때 |
8. 다른 알고리즘과 무엇이 다른가
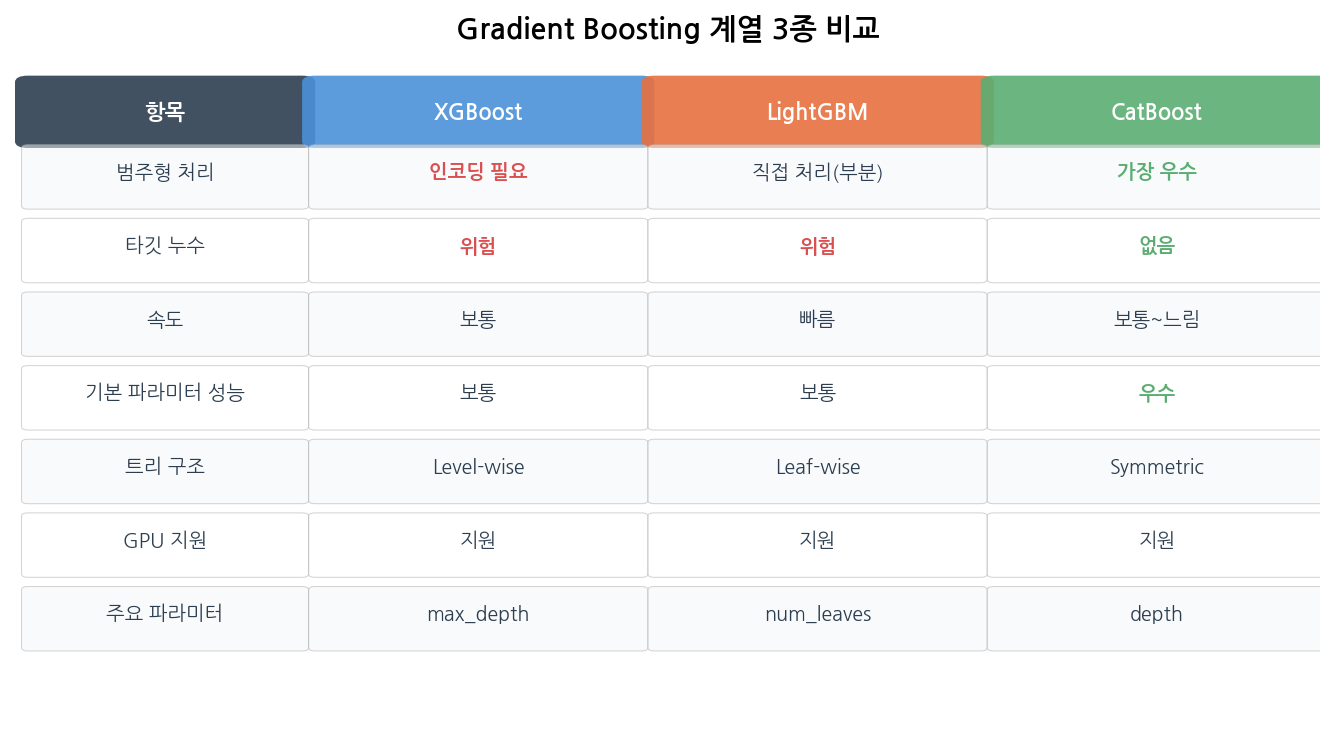
XGBoost vs LightGBM vs CatBoost
1
2
3
| XGBoost: 범주형 인코딩 필요, Level-wise, 안정적
LightGBM: 범주형 직접 처리, Leaf-wise, 가장 빠름
CatBoost: 범주형 가장 잘 처리, Symmetric Tree, 편향 없음
|
| 항목 | XGBoost | LightGBM | CatBoost |
|---|
| 범주형 처리 | ❌ 인코딩 필요 | ▲ 직접 처리 | ✅ 가장 우수 |
| 타깃 누수 | ⚠️ 위험 | ⚠️ 위험 | ✅ 없음 |
| 속도 | 보통 | 빠름 | 보통~느림 |
| 기본 파라미터 성능 | 보통 | 보통 | ✅ 우수 |
| GPU 지원 | ✅ | ✅ | ✅ |
9. 코드로 보기 — 타이타닉 생존 예측
1
2
3
4
5
6
7
8
9
10
11
12
| from catboost import CatBoostClassifier
cat = CatBoostClassifier(
iterations = 300, # 트리 수 (n_estimators에 해당)
learning_rate = 0.05, # 학습률(각 트리 기여도)
depth = 6, # 트리 깊이(대칭 트리라 중요)
l2_leaf_reg=3, # L2 정규화
cat_features = cat_cols, # 범주형 열 이름 목록
eval_metric = 'AUC',
random_seed = 0,
verbose = 100 # 100 반복마다 출력 (0이면 출력 없음)
)
|
| Parameter | Default | 역할 | 과적합 방향 |
|---|
iterations | 1000 | 트리 수 | 클수록 과적합 ↑ |
learning_rate | 자동 | 트리 기여도 | 클수록 과적합 ↑ |
depth | 6 | 트리 깊이 | 클수록 과적합 ↑ |
l2_leaf_reg | 3.0 | L2 정규화 | 클수록 과적합 ↓ |
border_count | 254 | 수치형 분기 구간 수 | - |
iterations : 트리를 몇 개 쌓을지- 값 변화별 효과
- 클수록 → 더 정교한 학습, 과적합 ↑
- Early Stopping과 함께 사용 권장
depth : Symmetric Tree의 깊이- 값 변화별 효과
- CatBoost는 Symmetric Tree라 depth=6이면 2⁶=64개 리프
- 기본값 6 권장, 10 이상은 과적합 위험
cat_features : 범주형 특성 열 지정- 열 이름(str) 또는 열 인덱스(int) 리스트
- 지정하지 않으면 수치형으로 처리
9-1. 전처리 — 범주형 인코딩 불필요
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| import pandas as pd
from sklearn.model_selection import train_test_split
titanic = pd.read_csv('./Data/Titanic.csv')
titanic['FamSize'] = titanic['SibSp'] + titanic['Parch']
use_cols = ['Survived', 'Pclass', 'Sex', 'Age', 'FamSize', 'Fare', 'Embarked']
titanic = titanic[use_cols].dropna(subset=['Age'])
titanic['Age'] = titanic['Age'].astype(int)
# ✅ CatBoost는 get_dummies() 불필요 — 문자열 그대로 사용
# Pclass, Sex, Embarked를 범주형으로 지정만 하면 됨
cat_cols = ['Pclass', 'Sex', 'Embarked']
for col in cat_cols:
titanic[col] = titanic[col].astype(str)
y = titanic['Survived']
X = titanic.drop('Survived', axis=1)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=0)
# ⚠️ CatBoost는 트리 기반 → 스케일링 불필요
# StandardScaler 생략
|
Note: CatBoost는 범주형 특성을 문자열 그대로 받을 수 있습니다. get_dummies()나 LabelEncoder() 없이 cat_features에 열 이름만 지정하면 됩니다.
9-2. 모델 학습
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| cat = CatBoostClassifier(
iterations = 300, # 트리 수 (n_estimators에 해당)
learning_rate = 0.05, # 학습률(각 트리 기여도)
depth = 6, # 트리 깊이(대칭 트리라 중요)
l2_leaf_reg=3, # L2 정규화
cat_features = cat_cols, # 범주형 열 이름 목록
eval_metric = 'AUC',
random_seed = 0,
verbose = 100 # 100 반복마다 출력 (0이면 출력 없음)
)
cat.fit(
X_train, y_train,
eval_set=(X_test, y_test),
early_stopping_rounds=50
)
|
9-3. 평가
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| from sklearn.metrics import (
accuracy_score, confusion_matrix,
classification_report, roc_auc_score
)
pred = cat.predict(X_test)
pred_prob = cat.predict_proba(X_test)[:, 1]
cfx = confusion_matrix(y_test, pred)
sensitivity = cfx[1, 1] / (cfx[1, 0] + cfx[1, 1])
specificity = cfx[0, 0] / (cfx[0, 0] + cfx[0, 1])
roc_auc = roc_auc_score(y_test, pred_prob)
print(f"Accuracy : {accuracy_score(y_test, pred) * 100:.2f}%")
print(f"Sensitivity : {sensitivity * 100:.2f}%")
print(f"Specificity : {specificity * 100:.2f}%")
print(f"ROC AUC : {roc_auc:.4f}")
print()
print(classification_report(y_test, pred, target_names=['Died (0)', 'Survived (1)']))
|
9-4. 특성 중요도
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| import pandas as pd
import matplotlib.pyplot as plt
importances = pd.Series(
cat.get_feature_importance(),
index=X.columns
).sort_values(ascending=True)
plt.figure(figsize=(7, 5))
importances.plot(kind='barh', color='steelblue')
plt.xlabel('Feature Importance')
plt.title('CatBoost Feature Importance')
plt.tight_layout()
plt.show()
|