1. 왜 등장했는가
선형 회귀는 특성들 사이에 상관관계가 높아지거나(다중공선성) 특성이 많아지면 계수가 불안정하게 폭발합니다.
Ridge는 손실 함수에 계수 제곱합 패널티(L2) 를 추가해 계수 크기를 균일하게 억제합니다.
Lasso와 달리 계수를 완전히 0으로 만들지 않고 모든 특성을 조금씩 유지합니다. (Hoerl & Kennard, 1970)
Lasso가 “불필요한 특성을 잘라내는 가위”라면,
Ridge는 “모든 특성을 고르게 작게 만드는 다이어트” 에 가깝습니다.
2. 핵심 아이디어 — 계수에 세금을 부과해 축소
Ridge는 본질적으로 계수 크기에 비례해 세금을 부과하는 선형 모델입니다.
계수(係數)란? 수식에서 변수 앞에 곱해지는 숫자입니다. 예를 들어 집값 = 520×면적 + (−410)×층수에서 520과 −410이 계수입니다. 이 숫자가 클수록 해당 변수가 결과에 미치는 영향이 크고, 음수이면 반대 방향으로 영향을 줍니다.
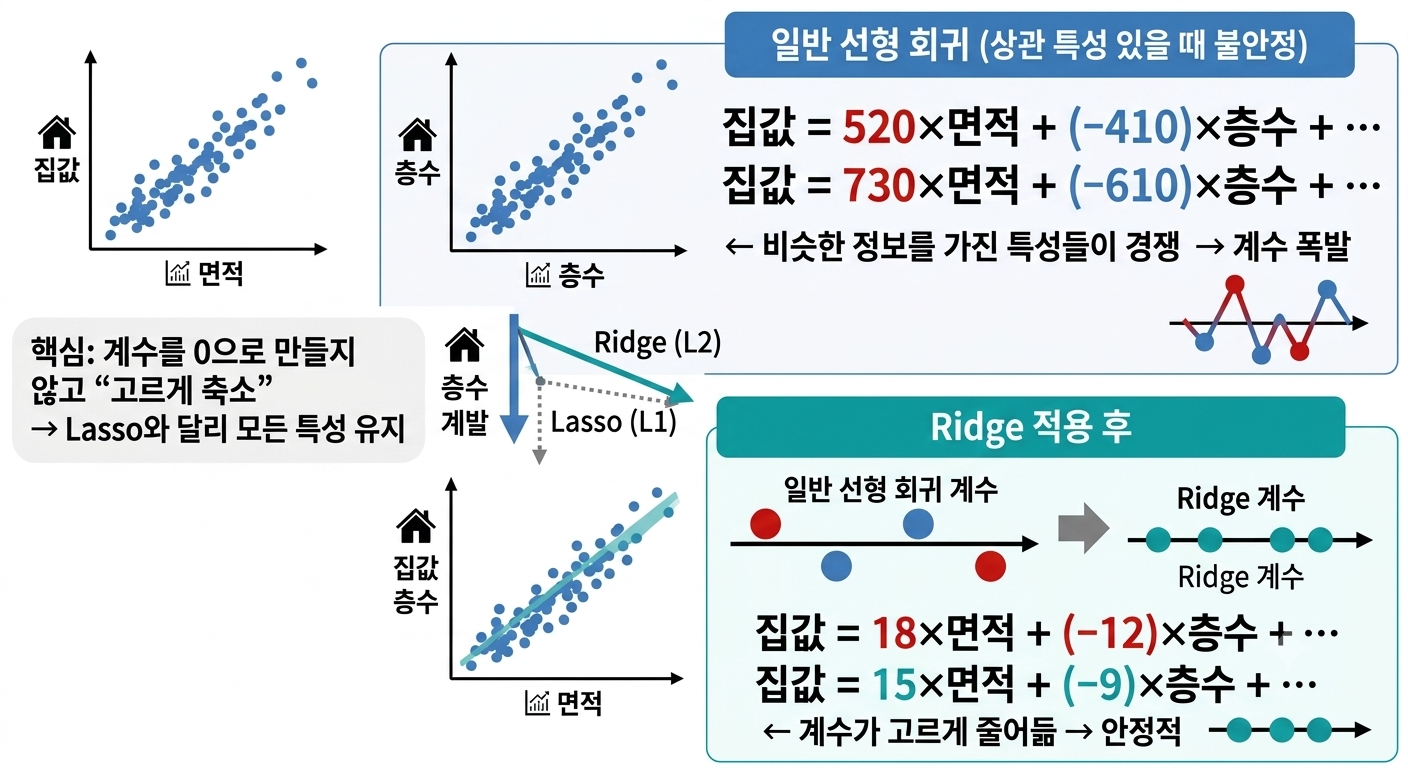
읽는 법:
이 그림은 왼쪽 위 → 오른쪽 위 → 오른쪽 아래 순서로 읽으면 됩니다.
왼쪽 위 (산점도 2개) — 면적과 층수가 서로 비슷한 정보를 담고 있음을 보여줍니다. 두 그래프 모두 우상향하는 모양이 비슷하죠.
오른쪽 위 (파란 박스) — 이처럼 비슷한 변수를 함께 쓰면 일반 회귀에서 계수가 520→730처럼 크게 요동치는 문제가 생깁니다.
가운데 화살표 — Ridge(L2)는 계수를 고르게 줄이고, Lasso(L1)는 일부 계수를 아예 0으로 만드는 차이를 나타냅니다.
오른쪽 아래 (초록 박스) — Ridge를 적용하면 계수가 18, −12처럼 작고 안정적인 값으로 바뀝니다. 크고 불안정하던 계수들이 고르게 줄어들면서 모델이 안정적으로 작동하게 됩니다.
3. 실제 예시로 보기 (분류 / 회귀)
예시 1 — 스팸 메일 분류 (분류)
1
2
3
4
5
6
7
8
9
10
11
12
13
| 특성: "광고" 단어 수, "무료" 단어 수, "클릭" 단어 수,
"지금" 단어 수, "할인" 단어 수
→ 스팸 메일에 자주 등장하는 단어들이라 서로 함께 나타나는 경향이 있음
일반 로지스틱 회귀 계수:
"광고": +9.8 / "무료": +11.2 ← 비슷한 단어끼리 경쟁해 계수 폭발
"클릭": -8.5 / "지금": +9.1 ← 음수/양수 뒤섞여 불안정
결과: 새 메일에 예측값이 들쑥날쑥함
Ridge 로지스틱 회귀 (alpha=1) 계수:
"광고": +1.2 / "무료": +1.4 ← 고르게 축소
"클릭": +1.1 / "지금": +1.3 ← 안정적
결과: 스팸일 확률을 일관되게 예측
|
예시 2 — 집값 예측 (회귀)
1
2
3
4
5
6
7
8
9
| 특성: 면적(㎡), 층수, 역거리(m), 학군점수, 소음(dB)
일반 선형 회귀 계수 (다중공선성 있을 때):
면적: +520.3 / 층수: -410.2 ← 과도하게 큰 음수
역거리: +380.5 / 학군: -290.1 ← 불안정
Ridge (alpha=10) 계수:
면적: +18.5 / 층수: -12.3 ← 안정적으로 줄어듦
역거리: +15.2 / 학군: -11.8 ← 안정적
|
4. 알고리즘 구성 요소
1
2
3
4
5
6
7
8
9
10
11
| 손실 함수:
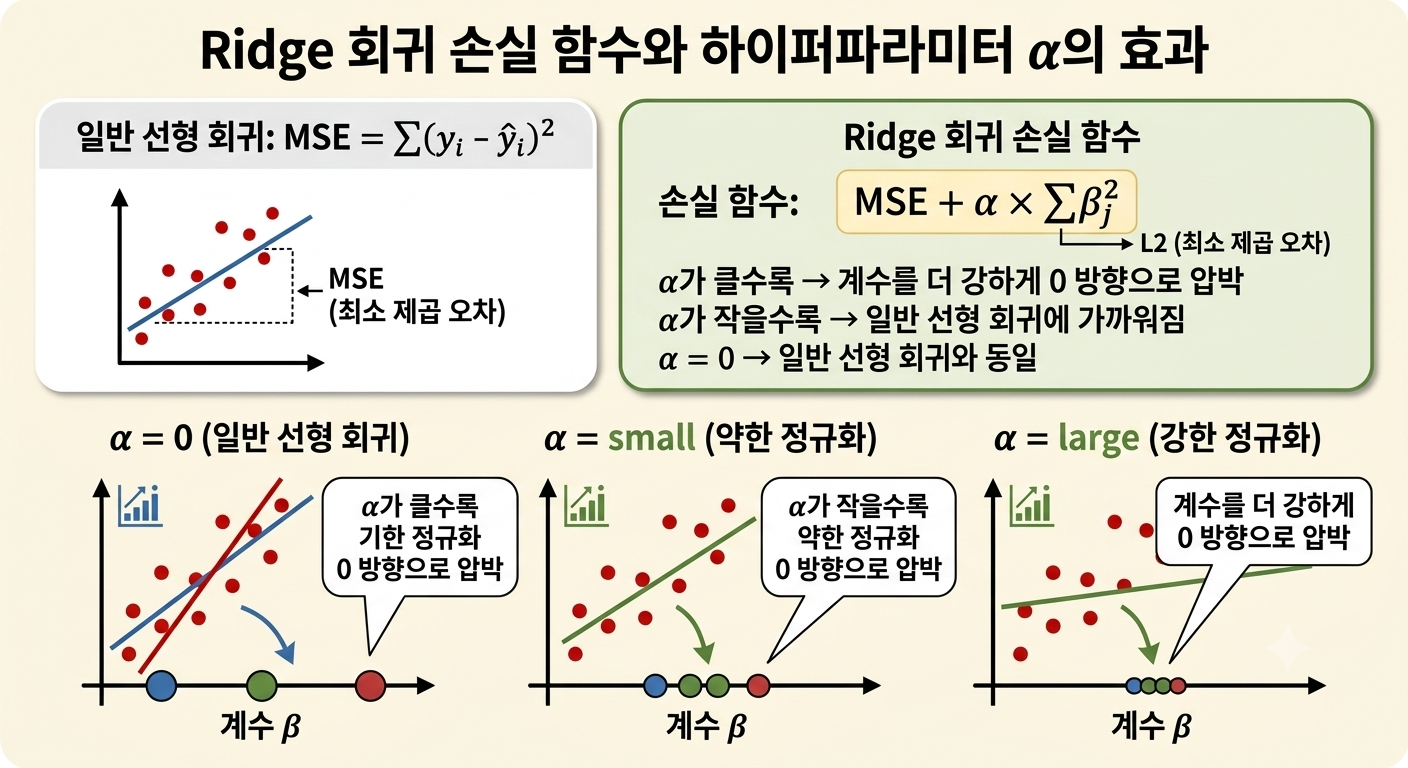
일반 선형 회귀: MSE = Σ(yᵢ - ŷᵢ)²
┌──────────────────────────────────────────────┐
│ Ridge = MSE + α × Σβⱼ² │
│ └── L2 패널티 (계수 제곱합) │
└──────────────────────────────────────────────┘
α가 클수록 → 계수를 더 강하게 0 방향으로 압박
α가 작을수록 → 일반 선형 회귀에 가까워짐
α = 0 → 일반 선형 회귀와 동일
|
읽는 법:
이 그림은 왼쪽 위 → 오른쪽 위 → 아래 3개 그래프 순서로 읽으면 됩니다. 왼쪽 위 (회색 박스) — 일반 선형 회귀는 예측값과 실제값의 차이(MSE, 오차의 제곱합)만 줄이려 합니다. 그래프에서 점과 선 사이의 간격이 MSE입니다. 오른쪽 위 (초록 박스) — Ridge는 MSE에 α × Σβ²를 더합니다. 여기서 α가 세율(패널티 강도)이고, Σβ²는 모든 계수를 제곱해서 더한 값입니다. 즉, 계수가 클수록 이 값이 커져 모델이 자동으로 계수를 줄이려 합니다. 아래 왼쪽 (α = 0) — 세금이 없으므로 계수들이 넓게 퍼져 있습니다. 일반 선형 회귀와 동일하며 과적합 위험이 있습니다. 아래 가운데 (α = small) — 세금이 약하게 부과되어 계수들이 조금 모입니다. 예측력을 유지하면서 계수를 살짝 줄인 상태입니다. 아래 오른쪽 (α = large) — 세금이 강하게 부과되어 계수들이 0 근처로 바짝 몰립니다. 계수가 지나치게 작아지면 오히려 예측력이 떨어질 수 있습니다.
| 구성 요소 | 설명 | 비유 |
|---|
| MSE | 예측 오차 최소화 | 정답에 가깝게 |
| L2 패널티 (Σβ²) | 계수 제곱합 최소화 | 계수가 커지면 세금 |
| α (알파) | 정규화 강도 | 세율 |
5. 어떻게 계수가 줄어드는가
5-1. L1 vs L2 기하학적 이해
1
2
3
4
5
6
7
8
9
| β₂ β₂
│ ●(MSE 최솟값) │ ●(MSE 최솟값)
│ / │ /
│/ │/
────────◆──────── β₁ ────────●──────── β₁
│╲ │
L1 (마름모) L2 (원형)
꼭짓점에서 만남 원 위에서 만남
→ 계수 = 0 발생 → 계수 ≒ 0, 정확히 0은 아님
|
L2 패널티는 원형 제약을 만들어 계수를 0에 가깝게 만들지만 정확히 0으로 만들지 않습니다.
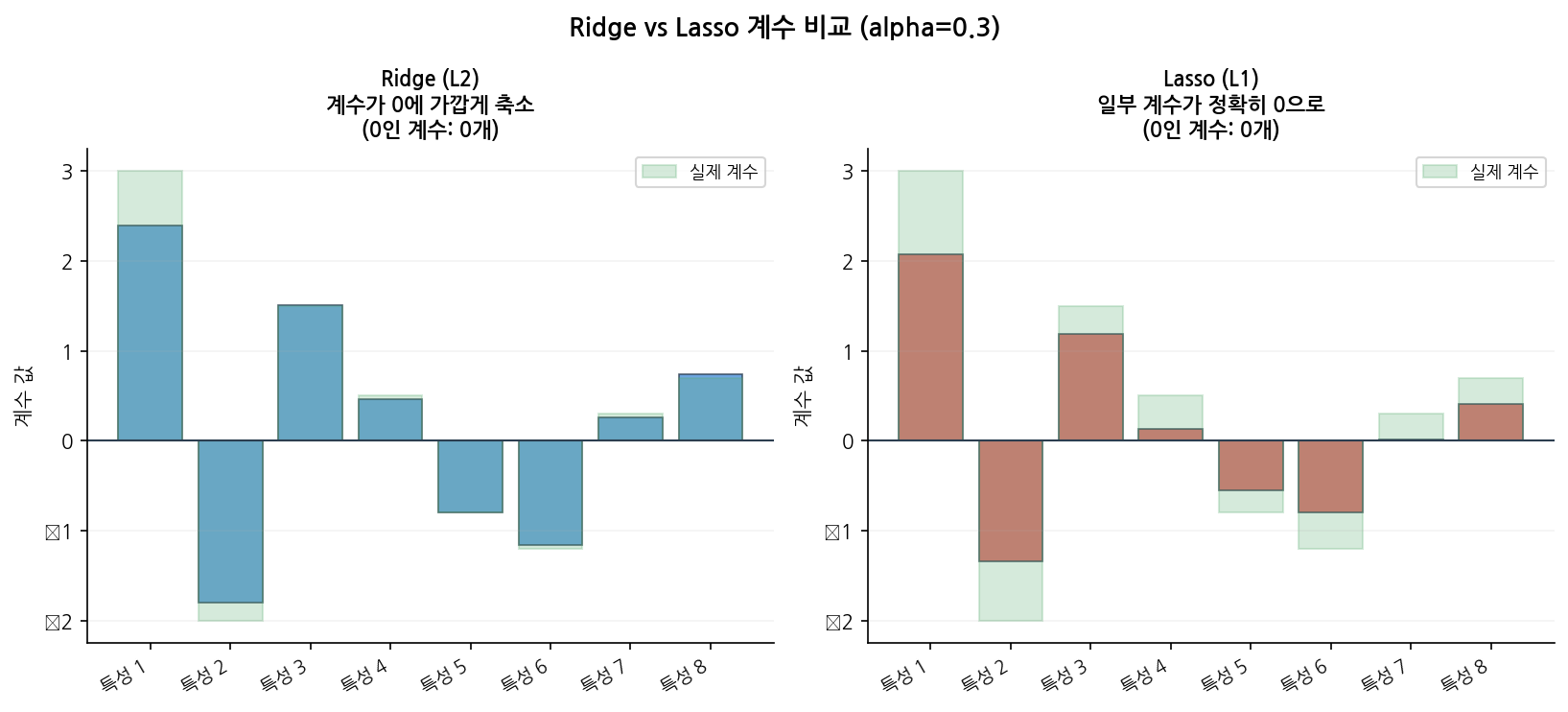
Ridge와 Lasso의 계수 시각화를 비교한 아래 그래프에서 이 차이를 직관적으로 확인할 수 있습니다.
읽는 법:
왼쪽(Ridge): 모든 특성의 계수가 0에 가깝게 줄어들지만, 정확히 0이 되는 특성은 없습니다. 상관 특성들의 계수가 비슷한 크기로 분산됩니다.
오른쪽(Lasso): 일부 특성의 계수가 정확히 0이 됩니다. 상관 특성 중 하나만 살아남고 나머지는 제거됩니다.
다중공선성이 있을 때는 Ridge가 더 안정적이고, 특성 선택이 필요할 때는 Lasso가 적합합니다.
\[\hat{\beta}_{Ridge} = (X^TX + \alpha I)^{-1}X^Ty\]
1
2
3
4
5
| 일반 선형 회귀: (X^TX)^{-1}X^Ty
Ridge: (X^TX + αI)^{-1}X^Ty
αI를 더함 → X^TX가 특이행렬이어도 해가 존재
→ 다중공선성 문제 해결, 항상 유일한 해
|
6. Ridge 장・단점
6-1. ✅ Ridge 장점
1
2
3
4
5
6
7
8
9
10
11
| 1. 다중공선성에 강함
→ 서로 상관된 특성들의 계수를 고르게 분배
2. 모든 특성 유지
→ 계수를 0으로 만들지 않음 → 정보 손실 없음
3. 안정적인 해
→ 특이행렬 문제 해결 → 항상 해 존재
4. 과적합 방지
→ 계수 크기 제어
|
6-2. ❌ Ridge가 약한 상황
1
2
3
4
5
6
7
8
9
| 1. 특성 선택이 필요할 때
→ 계수가 0이 되지 않음 → 불필요한 특성 제거 불가
→ Lasso 또는 ElasticNet 고려
2. 비선형 관계
→ 선형 모델의 한계
3. 해석이 필요한 경우
→ 모든 특성의 계수가 남아 해석 복잡
|
6-2-1. Ridge vs Lasso 선택 기준
1
2
3
4
5
6
7
8
9
| Ridge를 선택해야 할 때:
✅ 대부분의 특성이 타깃과 관련 있을 때
✅ 서로 상관된 특성이 많을 때 (다중공선성)
✅ 특성을 제거하지 않고 모두 유지하고 싶을 때
Lasso를 선택해야 할 때:
✅ 일부 특성만 타깃과 관련 있을 때
✅ 특성 수를 줄이고 싶을 때
✅ 특성 선택 + 모델링을 동시에 하고 싶을 때
|
해결책 :
1
2
3
4
5
6
7
8
9
10
11
12
13
| # 방법 1: RidgeCV로 최적 α 자동 탐색
from sklearn.linear_model import RidgeCV
ridge_cv = RidgeCV(
alphas=[0.001, 0.01, 0.1, 1.0, 10.0, 100.0],
cv=5
)
ridge_cv.fit(X_train, y_train)
print(f"Best alpha : {ridge_cv.alpha_:.4f}")
# 방법 2: 특성 선택이 필요하면 Lasso로 교체
from sklearn.linear_model import Lasso
lasso = Lasso(alpha=0.1)
|
7. 한눈에 요약
| 항목 | 내용 |
|---|
| 알고리즘 유형 | 지도학습 / 회귀 |
| 핵심 아이디어 | MSE + L2 패널티 → 계수를 0에 가깝게 축소 |
| 특성 선택 | ❌ 모든 특성 유지 (계수가 0이 되지 않음) |
| 스케일링 필요? | ✅ 필수 |
| Lasso와 차이 | Lasso는 0으로, Ridge는 0에 가깝게 |
| 핵심 파라미터 | alpha |
| 실전 사용 | 다중공선성 있을 때, 모든 특성 유지하고 싶을 때 |
8. 다른 알고리즘과 무엇이 다른가
Ridge vs Lasso vs ElasticNet
1
2
3
4
5
6
| 손실 함수 비교:
Linear: MSE
Ridge: MSE + α×Σβⱼ² (L2: 원형 제약, 계수 0에 가깝게)
Lasso: MSE + α×Σ|βⱼ| (L1: 마름모 제약, 계수 정확히 0으로)
ElasticNet: MSE + α×(ρ×Σ|βⱼ| + (1-ρ)×Σβⱼ²)
|
| 항목 | Ridge | Lasso | ElasticNet |
|---|
| 계수 = 0 | ❌ 0에 가깝게 | ✅ 정확히 0 | 일부 0 |
| 특성 선택 | ❌ | ✅ | ✅ 부분적 |
| 상관 특성 | ✅ 강함 | ⚠️ 하나만 선택 | ▲ 보통 |
| 다중공선성 | ✅ 강함 | ⚠️ 약함 | ▲ 보통 |
9. 코드로 보기 — 집값 예측 (회귀)
1
2
3
4
5
6
| from sklearn.linear_model import Ridge, RidgeCV
ridge = Ridge(
alpha = 1.0, # 정규화 강도 (클수록 계수가 0에 가까워짐)
fit_intercept = True
)
|
| Parameter | Default | 역할 | 과적합 방향 |
|---|
alpha | 1.0 | 정규화 강도 | 작을수록 과적합 ↑ |
fit_intercept | True | 절편 포함 여부 | - |
solver | 'auto' | 최적화 알고리즘 | - |
alpha : 가장 중요한 파라미터- 값 변화별 효과
- 클수록 → 계수 더 강하게 축소 → 단순한 모델
- 작을수록 → 일반 선형 회귀에 가까워짐
RidgeCV로 교차 검증 최적값 자동 탐색 권장- Options
float : 직접 지정array : 여러 값을 시도하려면 RidgeCV 사용
solver : 최적화 알고리즘'auto' : 데이터 크기에 따라 자동 선택 (기본값)'svd' : 소규모 데이터에 정확'saga' : 대규모 데이터에 효율적
9-1. 전처리
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| import pandas as pd
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
data = fetch_california_housing()
X = pd.DataFrame(data.data, columns=data.feature_names)
y = data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=0)
# ✅ Ridge는 계수 크기를 비교하므로 스케일링 필수
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
|
Note: Ridge는 계수의 제곱합으로 패널티를 계산하므로 StandardScaler가 반드시 필요합니다.
스케일링 없이는 단위가 큰 특성의 계수가 과도하게 패널티를 받습니다.
9-2. 모델 학습
1
2
3
4
5
| ridge = Ridge(
alpha = 1.0, # 정규화 강도 (클수록 계수가 0에 가까워짐)
fit_intercept = True
)
ridge.fit(X_train, y_train)
|
9-2-1. 교차 검증으로 최적 α 탐색
1
2
3
4
5
6
| ridge_cv = RidgeCV(
alphas = [0.001, 0.01, 0.1, 1.0, 10.0, 100.0],
cv = 5
)
ridge_cv.fit(X_train, y_train)
print(f"Best alpha : {ridge_cv.alpha_:.4f}")
|
9-3. 평가
1
2
3
4
5
6
7
| import numpy as np
from sklearn.metrics import mean_squared_error, r2_score
pred = ridge.predict(X_test)
print(f"R² : {r2_score(y_test, pred):.4f}")
print(f"RMSE: {np.sqrt(mean_squared_error(y_test, pred)):.4f}")
|
9-4. 계수 시각화
1
2
3
4
5
6
7
8
9
10
11
12
| import matplotlib.pyplot as plt
coef = pd.Series(ridge.coef_, index=data.feature_names).sort_values()
plt.figure(figsize=(7, 5))
colors = ['tomato' if c > 0 else 'steelblue' for c in coef]
coef.plot(kind='barh', color=colors)
plt.axvline(0, color='black', linewidth=0.8)
plt.xlabel('Coefficient')
plt.title(f'Ridge 계수 (alpha={ridge.alpha})')
plt.tight_layout()
plt.show()
|
9-5. α에 따른 계수 변화 (정규화 경로)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| import numpy as np
alphas = np.logspace(-3, 3, 100)
coefs = []
for a in alphas:
r = Ridge(alpha=a).fit(X_train, y_train)
coefs.append(r.coef_)
coefs = np.array(coefs)
plt.figure(figsize=(8, 5))
for i, name in enumerate(data.feature_names):
plt.semilogx(alphas, coefs[:, i], label=name)
plt.xlabel('alpha')
plt.ylabel('Coefficient')
plt.title('Ridge 정규화 경로 — α 증가할수록 계수가 0에 수렴')
plt.legend(loc='upper right', fontsize=8)
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
|
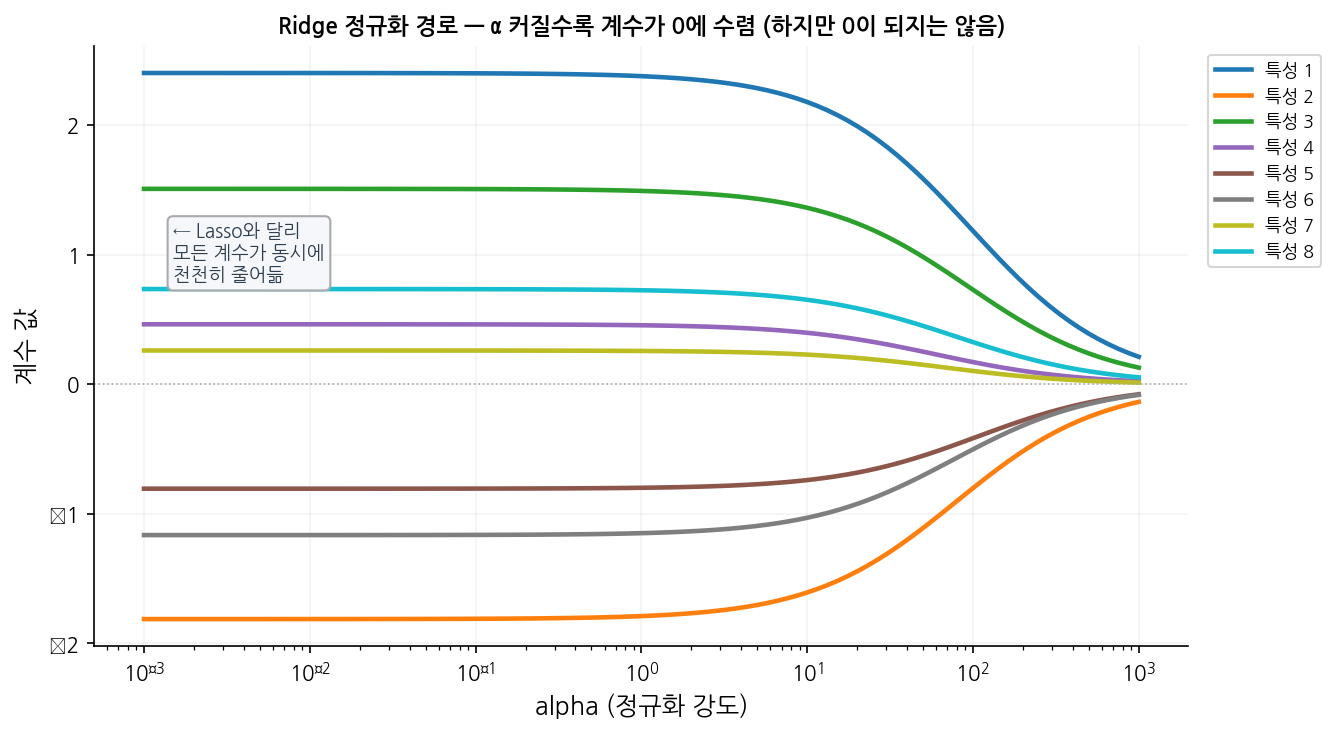
Lasso와 달리 모든 계수가 동시에 천천히 0에 가까워지는 것을 확인할 수 있습니다.
읽는 법:
x축(로그 스케일)은 α 값, y축은 각 특성의 계수입니다.
Lasso 경로와 달리, 모든 선이 α가 커짐에 따라 동시에 천천히 0에 수렴합니다.
어떤 특성도 먼저 0이 되지 않습니다 — 이것이 Ridge의 “특성 선택 없음” 특성입니다.
기울기가 큰(영향이 큰) 특성일수록 α에 따라 계수 변화가 가파릅니다.