
Pandas
1. Pandas란?
- 데이터 처리와 분석을 위한 라이브러리
- 행과 열로 이루어진 데이터 객체를 만들어 다룰 수 있음
- 대용량의 데이터들을 처리하는데 매우 편리
- Pandas 자료구조
- 시리즈(Series) : 1차원
- 데이터프레임(DataFrame) : 2차원
- 패널(Panel) : 3차원
# conda install pandas
import pandas as pd
2. Pandas 다루기
1. 파일 불러오기
- read_csv(‘경로’)
# pd.read_csv('경로')
titanic_df = pd.read_csv('./titanic_train.csv')
print(f'titanic 변수 type : {type(titanic_df)}')
titanic 변수 type : <class 'pandas.core.frame.DataFrame'>
2. Pandas DataFrame 만들기
- pd.DataFrame()
- 넘파이 ndarray, 리스트, 딕셔너리를 DataFrame으로 변환하기
import numpy as np
col_name = ['col1']
list = [1,2,3]
array = np.array(list)
print(f"array shape: {array.shape}\n")
# 리스트를 이용해 DataFrame 생성
df_list = pd.DataFrame(list, columns = col_name)
print(f"1차원 리스트로 만든 DataFrame:\n {df_list}\n")
# 넘파이 ndarray를 이용해 DataFrame 생성
df_array = pd.DataFrame(array, columns = col_name)
print(f"1차원 ndarray로 만든 DataFrame: \n{df_array}\n")
# 딕셔너리를 이용해 DataFrame 생성
dict = {'col1':[1, 11], 'col2':[2, 22], 'col3': [3,33]}
df_dict = pd.DataFrame(dict)
print(f"딕셔너리로 만든 DataFrame:\n {df_dict}")
array1 shape: (3,)
1차원 리스트로 만든 DataFrame:
col1
0 1
1 2
2 3
1차원 ndarray로 만든 DataFrame:
col1
0 1
1 2
2 3
딕셔너리로 만든 DataFrame:
col1 col2 col3
0 1 2 3
1 11 22 33
- DataFrame을 넘파이 ndarray, 리스트, 딕셔너리로 변환하기
print(f"DataFrame : \n {df}\n")
# DataFrame을 ndarray로 변환
array = df_dict.values
print(f"df_dict.values type: {type(array)} df_dict.values shape: {array.shape}\n")
# DataFrame을 리스트로 변환
list = df_dict.values.tolist()
print(f"df_dict.values.tolist() type: {type(list)}")
print(f"list: {list}\n")
# DataFrame을 딕셔너리로 변환
dict = df_dict.to_dict('list')
print(f"df_dict.to_dict() type: {type(dict)}")
print(f"dict: {dict}")
DataFrame :
col1 col2 col3
0 1 2 3
1 11 22 33
df_dict.values type: <class 'numpy.ndarray'> df_dict.values shape: (2, 3)
df_dict.values.tolist() type: <class 'list'>
list: [[1, 2, 3], [11, 22, 33]]
df_dict.to_dict() type: <class 'dict'>
dict: {'col1': [1, 11], 'col2': [2, 22], 'col3': [3, 33]}
3. DataFrame의 상위 N개의 row를 반환
- DF.head(N)
# Df.head(N)
titanic_df.head(3)
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th… | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S4. |
4. DataFrame의 하위 N개의 row를 반환
- DF.tail(N)
# Df.tail(N)
titanic_df.tail(3)
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 888 | 889 | 0 | 3 | Johnston, Miss. Catherine Helen “Carrie” | female | NaN | 1 | 2 | W./C. 6607 | 23.45 | NaN | S |
| 889 | 890 | 1 | 1 | Behr, Mr. Karl Howell | male | 26.0 | 0 | 0 | 111369 | 30.00 | C148 | C |
| 890 | 891 | 0 | 3 | Dooley, Mr. Patrick | male | 32.0 | 0 | 0 | 370376 | 7.75 | NaN | Q |
5. DataFrame 크기 확인
- DF.shape
# DF.shape()
print(f"DataFrame 크기 : {titanic_df.shape}")
DataFrame 크기 : (891, 12)
6. DataFrame의 총 데이터 건수와 데이터 타입, Null 건수
- DF.info( )
# Df.info()
titanic_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
7. 칼러별 숫자형 데이터값의 n-percentile분포도, 평균값, 최댓값, 최솟값
- DF.describe( )
# DF.describe()
titanic_df.describe()
| PassengerId | Survived | Pclass | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|
| count | 891.000000 | 891.000000 | 891.000000 | 714.000000 | 891.000000 | 891.000000 | 891.000000 |
| mean | 446.000000 | 0.383838 | 2.308642 | 29.699118 | 0.523008 | 0.381594 | 32.204208 |
| std | 257.353842 | 0.486592 | 0.836071 | 14.526497 | 1.102743 | 0.806057 | 49.693429 |
| min | 1.000000 | 0.000000 | 1.000000 | 0.420000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 223.500000 | 0.000000 | 2.000000 | 20.125000 | 0.000000 | 0.000000 | 7.910400 |
| 50% | 446.000000 | 0.000000 | 3.000000 | 28.000000 | 0.000000 | 0.000000 | 14.454200 |
| 75% | 668.500000 | 1.000000 | 3.000000 | 38.000000 | 1.000000 | 0.000000 | 31.000000 |
| max | 891.000000 | 1.000000 | 3.000000 | 80.000000 | 8.000000 | 6.000000 | 512.329200 |
8. 특정 컬럼을 추출
# Df['C_N']
one = titanic_df['Age']
print(f"one : \n{one}\n")
print(f"one type: {type(one)}")
# DF[['C_N']]
two = titanic_df[['Age']]
print(f"two : \n{two}\n")
print(f"two type: {type(two)}")
one :
0 22.0
1 38.0
2 26.0
3 35.0
4 35.0
...
886 27.0
887 19.0
888 NaN
889 26.0
890 32.0
Name: Age, Length: 891, dtype: float64
one type: <class 'pandas.core.series.Series'>
two :
Age
0 22.0
1 38.0
2 26.0
3 35.0
4 35.0
.. ...
886 27.0
887 19.0
888 NaN
889 26.0
890 32.0
[891 rows x 1 columns]
two type: <class 'pandas.core.frame.DataFrame'>
9. 메서드를 호출하면 해당 칼럼값의 유형과 건수를 확인 가능
- DF[‘C_N’].value_counts( )
- dropna : 결측값 포함(False) or 제외(True[default])
# DF['Column_Name'].value_counts()
value_counts = titanic_df['Pclass'].value_counts()
value_counts
3 491
1 216
2 184
Name: Pclass, dtype: int64
print(f"titanic_df['Embarked']의 전체 데이터 건수 : {titanic_df['Embarked'].shape[0]}")
print(f"dropna = True : \n{titanic_df['Embarked'].value_counts()}")
print(f"dropna = False : \n{titanic_df['Embarked'].value_counts(dropna=False)}")
titanic_df['Embarked'] 데이터 건수 : 891
dropna = True :
S 644
C 168
Q 77
Name: Embarked, dtype: int64
dropna = False :
S 644
C 168
Q 77
NaN 2
Name: Embarked, dtype: int64
10. Series
- Index와 단 하나의 칼럼으로 구성된 데이터 셋
titanic_pclass = titanic_df['Pclass']
print(type(titanic_pclass))
print('Series의 Index | Series의 데이터값')
titanic_pclass.head()
<class 'pandas.core.series.Series'>
Series의 Index | Series의 데이터값
0 3
1 1
2 3
3 1
4 3
Name: Pclass, dtype: int64
-
연산
Series_Age = titanic_df['Age'] print(f"Age_Max : {Series_Age.max()}") print(f"Age_Min : {Series_Age.min()}") print(f"Age_Sum : {Series_Age.sum()}")Age_Max : 80.0 Age_Min : 0.42 Age_Sum : 21205.17
11. Index 객체
- DataFrame, Series의 레코드를 고유하게 식별하는 객체
# Index 객체 추출
indexes = titanic_df.index
print(indexes)
RangeIndex(start=0, stop=891, step=1)
3. DataFrame의 칼럼 데이터 세트 생성과 수정
-
Column 데이터 생성
titanic_df.head()PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked 0 1 0 3 Braund, Mr. Owen Harris male 22.0 1 0 A/5 21171 7.2500 NaN S 1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th… female 38.0 1 0 PC 17599 71.2833 C85 C 2 3 1 3 Heikkinen, Miss. Laina female 26.0 0 0 STON/O2. 3101282 7.9250 NaN S 3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35.0 1 0 113803 53.1000 C123 S 4 5 0 3 Allen, Mr. William Henry male 35.0 0 0 373450 8.0500 NaN S # [Age_0] column 추가 titanic_df['Age_0'] = 0 titanic_df.head()PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked Age_0 0 1 0 3 Braund, Mr. Owen Harris male 22.0 1 0 A/5 21171 7.2500 NaN S 0 1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th… female 38.0 1 0 PC 17599 71.2833 C85 C 0 2 3 1 3 Heikkinen, Miss. Laina female 26.0 0 0 STON/O2. 3101282 7.9250 NaN S 0 3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35.0 1 0 113803 53.1000 C123 S 0 4 5 0 3 Allen, Mr. William Henry male 35.0 0 0 373450 8.0500 NaN S 0DataFrame 데이터 삭제 -
DataFrame 데이터 삭제
-
DataFrame.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors=’raise’)
-
label : column name
-
axis : 0은 row 방향 1은 column 방향 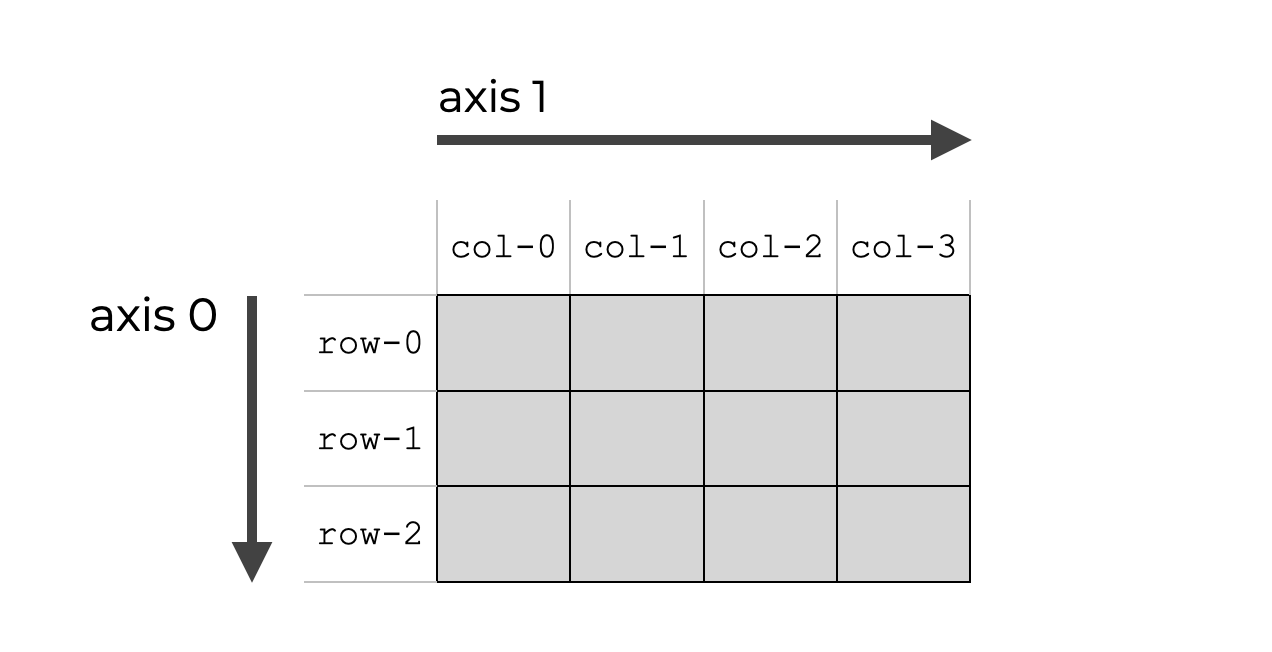
-
inplace :
- True : 자기 자신의 DataFrame의 데이터는 삭제
- Fales : 자기 자신의 DataFrame의 데이터 삭제하지 않는다.
-
-
4. 데이터 셀렉션 및 필터링
1. DataFrame의 연산자
print(f"단일 컬럼 데이터 추출:\n{titanic_df['Pclass'].head()}\n")
print(f"여러 칼럼의 데이터 추출:\n{titanic_df[['Survived', 'Pclass']].head()}")
단일 컬럼 데이터 추출:
0 3
1 1
2 3
3 1
4 3
Name: Pclass, dtype: int64
여러 칼럼의 데이터 추출:
Survived Pclass
0 0 3
1 1 1
2 1 3
3 1 1
4 0 3
2. Data 선택
-
슬라이싱
titanic_df[0:2]PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked 0 1 0 3 Braund, Mr. Owen Harris male 22.0 1 0 A/5 21171 7.2500 NaN S 1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th… female 38.0 1 0 PC 17599 71.2833 C85 C -
특정 데이터 추출
# titanic_df 중 Pclass 컬럼이 3인 데이터 추출 titanic_df[titanic_df['Pclass']==3].head()PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked 0 1 0 3 Braund, Mr. Owen Harris male 22.0 1 0 A/5 21171 7.2500 NaN S 2 3 1 3 Heikkinen, Miss. Laina female 26.0 0 0 STON/O2. 3101282 7.9250 NaN S 4 5 0 3 Allen, Mr. William Henry male 35.0 0 0 373450 8.0500 NaN S 5 6 0 3 Moran, Mr. James male NaN 0 0 330877 8.4583 NaN Q 7 8 0 3 Palsson, Master. Gosta Leonard male 2.0 3 1 349909 21.0750 NaN S
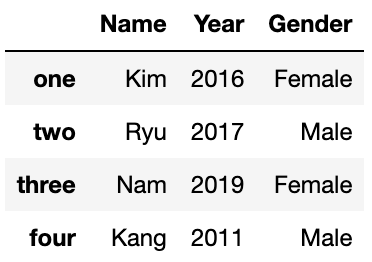
3. DataFrame.iloc 연산자
-
DF.iloc[row_index, column_index]
-
위치(Location) 기반 인덱싱 방식
data_dfName Year Gender one Kim 2016 Female two Ryu 2017 Male three Nam 2019 Female four Kang 2011 Male # DF.iloc[행, 열] data_df.iloc[0,0]'Kim'


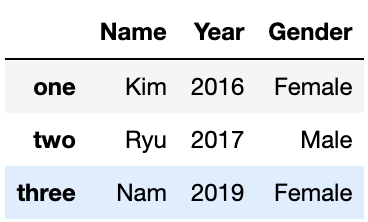
4. DataFrame.loc 연산자
- DF.loc[인덱스값, 컬럼명]
- 명칭(Label) 기반 인덱싱 방식
data_df.loc['one','Name']
'Kim'

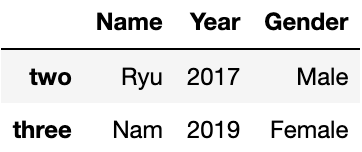
5. 불린 인덱싱
- and 조건일 때는 &
-
or 조건일 때는 - Not 조건일 때는 ~
titanic_boolean = titanic_df[titanic_df['Age'] > 60]
print(type(titanic_boolean))
titanic_boolean.head()
<class 'pandas.core.frame.DataFrame'>
Out[126]:
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 33 | 34 | 0 | 2 | Wheadon, Mr. Edward H | male | 66.0 | 0 | 0 | C.A. 24579 | 10.5000 | NaN | S |
| 54 | 55 | 0 | 1 | Ostby, Mr. Engelhart Cornelius | male | 65.0 | 0 | 1 | 113509 | 61.9792 | B30 | C |
| 96 | 97 | 0 | 1 | Goldschmidt, Mr. George B | male | 71.0 | 0 | 0 | PC 17754 | 34.6542 | A5 | C |
| 116 | 117 | 0 | 3 | Connors, Mr. Patrick | male | 70.5 | 0 | 0 | 370369 | 7.7500 | NaN | Q |
| 170 | 171 | 0 | 1 | Van der hoef, Mr. Wyckoff | male | 61.0 | 0 | 0 | 111240 | 33.5000 | B19 | S |
titanic_df[ (titanic_df['Age'] > 60) & (titanic_df['Pclass'] == 1) & (titanic_df['Sex']=='female') ]
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 275 | 276 | 1 | 1 | Andrews, Miss. Kornelia Theodosia | female | 63.0 | 1 | 0 | 13502 | 77.9583 | D7 | S |
| 829 | 830 | 1 | 1 | Stone, Mrs. George Nelson (Martha Evelyn) | female | 62.0 | 0 | 0 | 113572 | 80.0000 | B28 | NaN |
6. 정렬, Aggregation 함수, GroupBy 함수
- DataFrame, Series의 정렬 - sort_values()
- by : 특정 column
- ascending
- True : 오름차순(Default 값)
- False : 내림차순
- inplace
- True : DataFrame의 정렬 결과를 그대로 적용
- False : sort_values()를 호출한 DataFrame은 그대로 유지하며 정렬된 DataFrame의 결과를 반환
titanic_sorted = titanic_df.sort_values(by = ['Name'])
titanic_sorted.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 845 | 846 | 0 | 3 | Abbing, Mr. Anthony | male | 42.0 | 0 | 0 | C.A. 5547 | 7.55 | NaN | S |
| 746 | 747 | 0 | 3 | Abbott, Mr. Rossmore Edward | male | 16.0 | 1 | 1 | C.A. 2673 | 20.25 | NaN | S |
| 279 | 280 | 1 | 3 | Abbott, Mrs. Stanton (Rosa Hunt) | female | 35.0 | 1 | 1 | C.A. 2673 | 20.25 | NaN | S |
| 308 | 309 | 0 | 2 | Abelson, Mr. Samuel | male | 30.0 | 1 | 0 | P/PP 3381 | 24.00 | NaN | C |
| 874 | 875 | 1 | 2 | Abelson, Mrs. Samuel (Hannah Wizosky) | female | 28.0 | 1 | 0 | P/PP 3381 | 24.00 | NaN | C |
- Aggregation 함수 적용
- min( ) : 최소 값
- max( ) : 최대 값
- sum( ) : 합계
- count( ) : 개수
- mean( ) : 평균
- groupby( ) 적용
titanic_groupby = titanic_df.groupby(by = 'Pclass').count()
titanic_groupby
| PassengerId | Survived | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Pclass | |||||||||||
| 1 | 216 | 216 | 216 | 216 | 186 | 216 | 216 | 216 | 216 | 176 | 214 |
| 2 | 184 | 184 | 184 | 184 | 173 | 184 | 184 | 184 | 184 | 16 | 184 |
| 3 | 491 | 491 | 491 | 491 | 355 | 491 | 491 | 491 | 491 | 12 | 491 |
titanic_df.groupby('Pclass')['Age'].agg([max,min])
| max | min | |
|---|---|---|
| Pclass | ||
| 1 | 80.0 | 0.92 |
| 2 | 70.0 | 0.67 |
| 3 | 74.0 | 0.42 |
5. 결손 데이터 처리하기
- 결손 데이터 : 칼럼에 값이 없는, 즉 NULL인 경우(NAN)
- isna()로 결손 데이터 여부 확인
titanic_df.isna().sum()
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
- fillna()로 결손 데이터 대체하기
# 결측값 => C000 로 대체
titanic_df['Cabin'] = titanic_df['Cabin'].fillna('C000')
titanic_df.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | C000 | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th… | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | C000 | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | C000 | S |
참고 파이썬 머신러닝 완벽 가이드