Transformer
Transformer
By Seung Ho Ryu (Comment. Jung In Seo)
Reference
- 파이썬 텍스트 마이닝 완벽 가이드(Section 13) - 텐서플로 2와 머신러닝으로 시작하는 자연어 처리(Section 6) - 케라스 창시자에게 배우는 딥러닝(2판)(Section 11.5)1. Seq2Seq(Sequence to Sequence)
- 시퀀스 형태의 입력값을 시퀀스 형태의 출력으로 만들 수 있게 하는 모델
Sequence: 단어, 문자, 또는 기타 연속된 데이터 포인트들의 집합
- 인코더(Encoder)와 디코더(Decoder)를 주요 구성요소로 가지고 있음
- ex) “hello world”에서 “bonjour le monde”로 번역하는 과정
- <start> : 문장의 시작 혹은 번역의 시작을 알리는 토큰
- <end> : 문장의 마지막을 알리는 토큰

- Encoder
- 모든 단어를 순차적으로 입력 받은 뒤 마지막에 이 모든 단어들의 정보를 압축해서 담은
Context Vector생성 Context Vector: 인코더 RNN셀의 마지막 시점의 은닉 상태(인코더 부분의 정보를 요약해 담고 있는 벡터)
- 모든 단어를 순차적으로 입력 받은 뒤 마지막에 이 모든 단어들의 정보를 압축해서 담은
- Decoder
- Context Vector와 <start>를 받아 순차적으로 토큰을 만들어 최종 출력 시퀀스를 만들어냄
- [ 훈련 과정 ]
- Encoder의 입력에 대응하는 실제값을 입력으로 사용
- 디코더의 입력을 이전 시점의 은닉상태와 현재 시점의 실제 값으로 사용(교사강요)
- 훈련 과정에서 이전 시점의 예측 값을 사용하다가 예측이 잘못되면 Decoder 전체 예측이 잘못될 수도 있고, 훈련 시간이 느려지기 때문입니다.
- [ 실제 번역 과정 ]
- 디코더의 입력이 이전 시점의 은닉상태와 이전 시점의 예측 값
- ex) “hello world”에서 “bonjour le monde”로 번역하는 과정
- 가장 많이 활용되는 분야
- 기계 번역(Machine translation) : 입력 시퀀스를 입력 문장, 출력 시퀀스를 번역 문장으로 구성
- 챗봇(Chatbot) : 입력 시퀀스를 질문, 출력 시퀀스를 대답으로 구성
- 단점
- RNN의 기울기 소실 문제
- 하나의 고정된 크기의 벡터에 모든 정보를 압축하려고 하여 정보 손실이 발생
- EX) “I went to school yesterday” → “나는 어제 학교에 갔다”
- 마지막 단어인 ‘갔다’를 예측할 때, 이 단어에 가장 많은 영향을 미치는 원문의 단어는 ‘went’이다. 그러나 이 정보는 다른 단어들과 함께 문맥 벡터에 숨어있다.
- ‘went’가 ‘갔다’의 예측에 직접 관여하기 위하여 고안된 것이 Attention 메커니즘이다.
- EX) “I went to school yesterday” → “나는 어제 학교에 갔다”
2. Attention
- 디코더에서 출력 단어를 예측하는 매 시점(time step)마다, 인코더에서의 전체 입력 문장을 다시 한 번 참고한다는 점
- 단, 전체 입력 문장을 전부 다 동일한 비율로 참고하는 것이 아닌, 해당 시점에서 예측해야할 단어와 연관이 있는 단어 부분을 좀 더 집중(Attention)해서 참고
- 즉, ‘bonjour’를 예측한다면 ‘bonjour’과 연관성을 확인하여 가장 연관있는 단어에 집중해서 참고하는 것임
- Attention은 디코더의 출력 단어를 예측하기 위해서 전체 입력 문장을 어텐션 값(Attention Value)을 통해 참고함
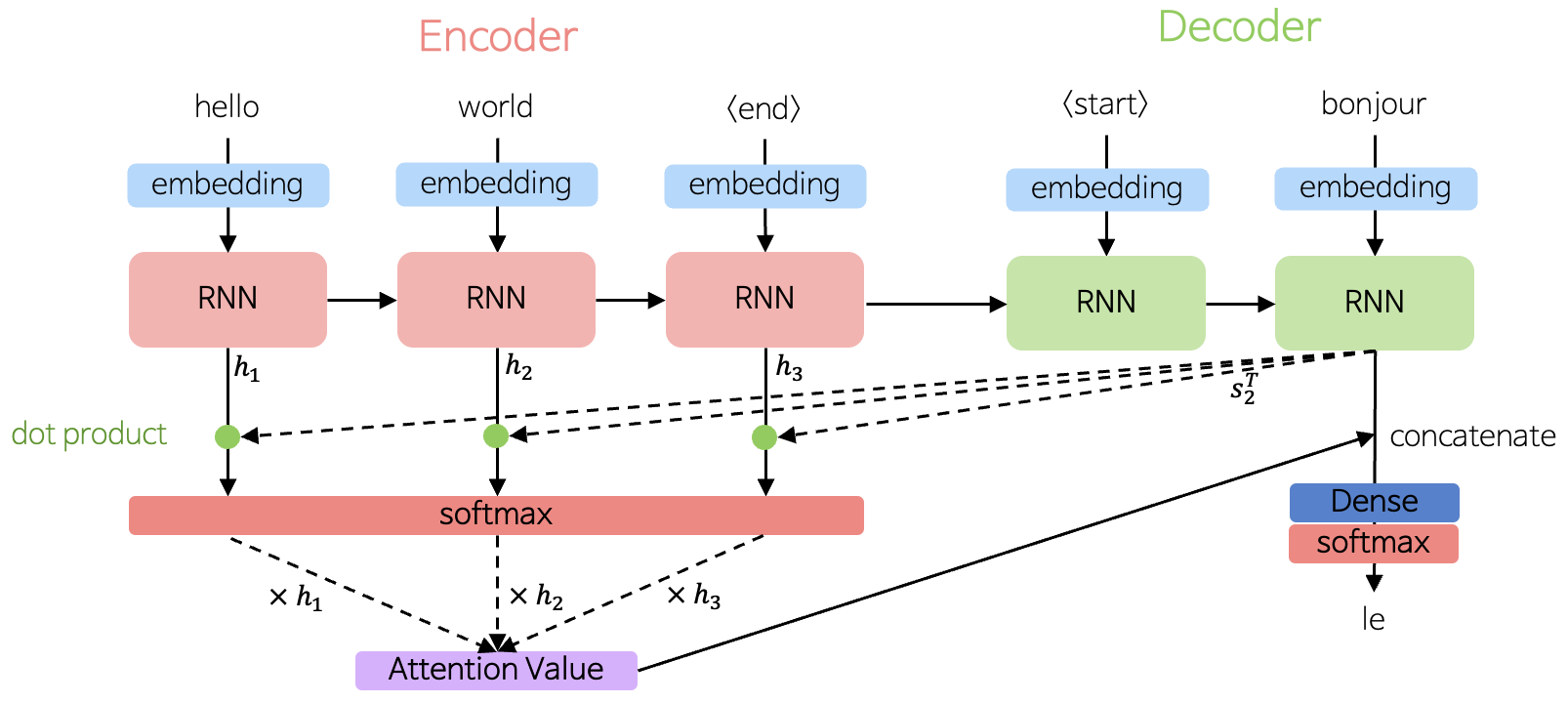
- $t$시점의 Attention Value
- t시점의 디코더의 은닉 상태와 인코더의 모든 은닉상태를 내적 곱하여 Attention Score를 구함
- $Attention Score(s_t, h_i) = s_t^Th_i$
- $Attention Score$ : $s_t$와 $h_i$의 유사도 값
- $s^T_t$ : Decoder의 $t$시점의 은닉 상태
- $h_i$ : Encoder의 $i$ 번째 은닉 상태
- $Attention Score(s_t, h_i) = s_t^Th_i$
- 모든 $Attention Score$를 $Softmax$함수에 적용
- $\alpha^t = softmax([s_t^Th_1, s_t^Th_2, …, s_t^Th_N])$
- 각 인코더의 은닉 상태와 $\alpha^t$를 가중합
- $a_t = \sum^N_{i=1}a_i^th_i$
- $a_t$ : Decoder의 $t$시점의 Attention Value
- $a_t = \sum^N_{i=1}a_i^th_i$
- t시점의 디코더의 은닉 상태와 인코더의 모든 은닉상태를 내적 곱하여 Attention Score를 구함
- 단, 전체 입력 문장을 전부 다 동일한 비율로 참고하는 것이 아닌, 해당 시점에서 예측해야할 단어와 연관이 있는 단어 부분을 좀 더 집중(Attention)해서 참고
- 단점
- Decoder부분에서 문장이 길어지면 정보 손실이 발생
- 즉, 거리에 영향을 받는것은 지속적인 문제
- RNN의 기울기 소실 문제
- Decoder부분에서 문장이 길어지면 정보 손실이 발생
3. Transformer
- Seq2Seq모형에서 순환 신경망을 사용하지 않고 Attention으로만 구성한 모형

- 하이퍼파라미터
- $V$ : 어휘 크기(훈련 데이터의 고유 단어 수)
- $d_{model}$ : 임베딩 벡터의 크기(차원)
- $num_layers$ : 인코더 & 디코더 개수
- $num_heads$ : 어텐션 개수
- $d_{ff}$ : 피드 포워드 시경망의 은닉층 개수
- 주요 구성
- 토큰 임베딩(Token Embedding)
- 위치 인코딩(Positional Encoding)
- 셀프 어텐션(Self-Attention)
- 멀티 헤드 어텐션(Multi-Head Attention)
- 잔차연결(Residual Connection) & 정규화(Layer Normalization)
- 피드 포워드 신경망(Feed forward network)
3-1. Encoder
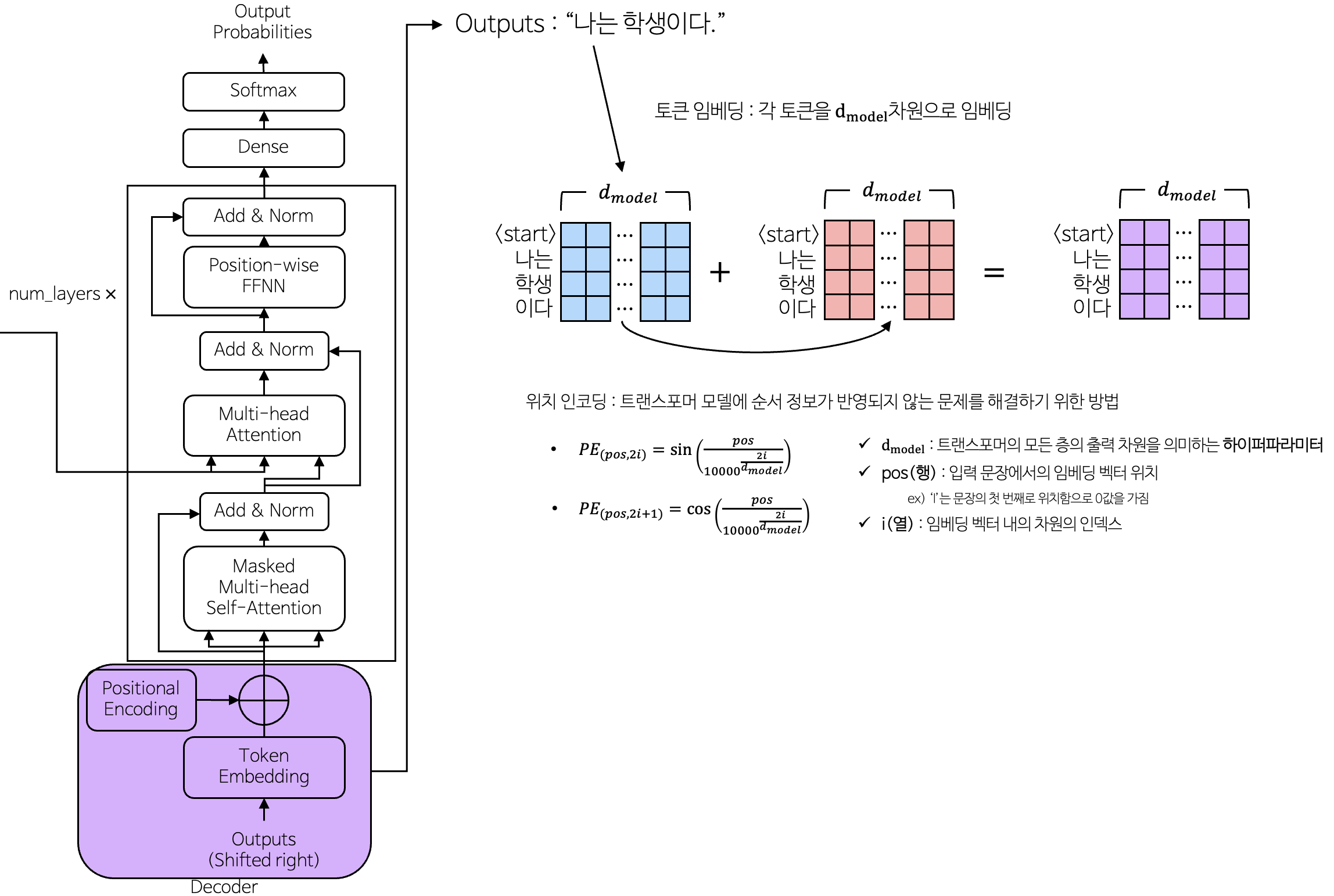
3-1-1. 토큰 임베딩(Token Embedding) & 위치 인코딩(Positional Encoding)
- 토큰 임베딩 벡터값에 위치 인코딩의 벡터값을 더하여 연산
- 토큰 임베딩
- 입력 토큰을 컴퓨터가 이해할 수 있도록 행렬 값으로 변경
- 위치 인코딩
- 토큰의 위치 정보
- 토큰 임베딩
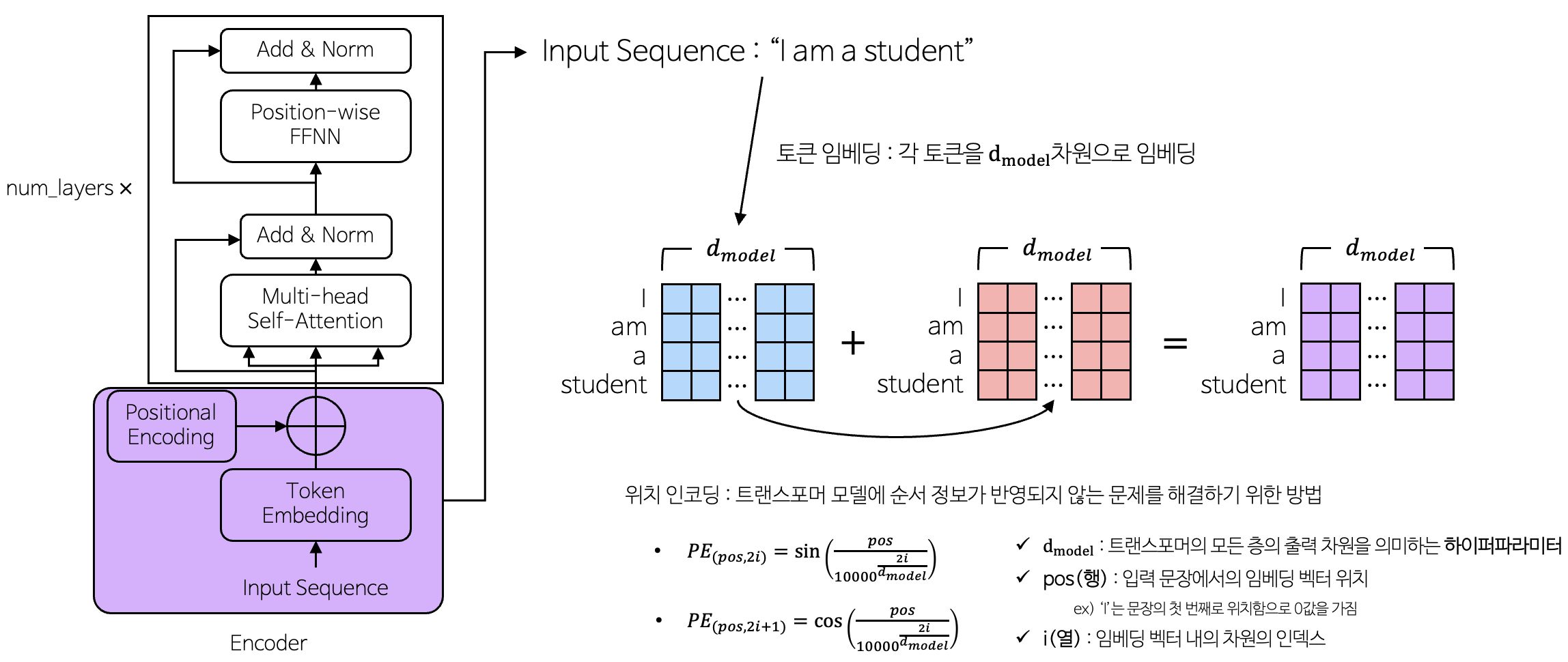
3-1-1-1. 위치 인코딩
- 위치 인코딩은 왜 필요한가?
- 트랜스포머 이전의 모델인 RNN과 LSTM은 순차적으로 문장을 처리하는 특징을 가짐
- 트랜스 포머의 경우 입력되는 문장을 순차적으로 처리하지 않고 병렬로 한번에 처리하는 특징을 가짐
- 병렬로 처리하여 연산을 빨리 수행하는 장점이 있지만, 단어의 위치를 알 수 없다는 단점이 존재
- 이를 해결하기 위하여 위치 인코딩이 수행이 됨
- 단어의 위치 정보가 중요한 이유?
- “Dogs chase cats” : 개들이 고양이들을 쫒는다.
- “Cats chase dogs” : 고양이들이 개들을 쫒는다.
- 위 두 문장을 구성하는 단어들은 같은데 단어의 위치에 의해 두 문장의 뜻이 달라지는 문제가 발생, 따라서 단어의 위치 정보는 중요함
- 위치 인코딩에 sine & cosine함수를 사용하는 이유?
- 의미 정보가 변하지 않도록 위치 벡터 값이 너무 크면 안됨
- sine & cosine 함수는 $-1 \sim 1$사이를 반복하는 주기함수 이므로, 값이 너무 커지는 조건을 만족시킴
- 같은 위치의 토큰은 항상 같은 위치 벡터 값을 가져야 함, 하지만 서로 다른 위치의 토큰은 위치 벡터 값이 서로 달라야함
- 다양한 주기의 sine & cosine 함수를 동시에 사용하여 서로 다른 위치 값을 가지게 함
- 의미 정보가 변하지 않도록 위치 벡터 값이 너무 크면 안됨
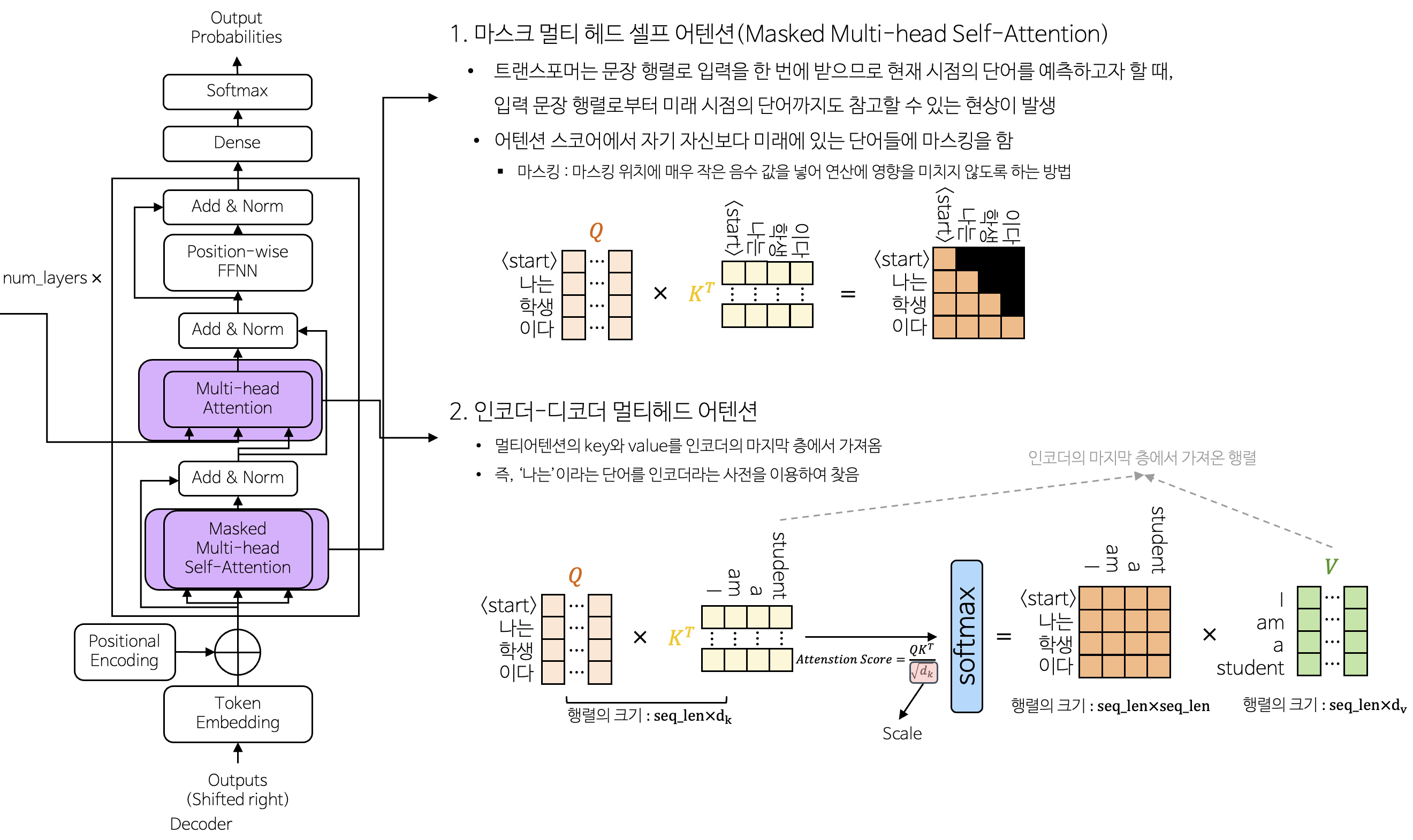
3-1-2. 멀티 헤드 어텐션(Multi-head Attention)
- 입력 시퀀스의 각 단어가 시퀀스 내 다른 모든 단어들과의 관계를 고려하여 중요한 정보를 추출하는 데 사용
여러 개의 Self-Attention을 통하여 서로 다른 정보를 추출 가능
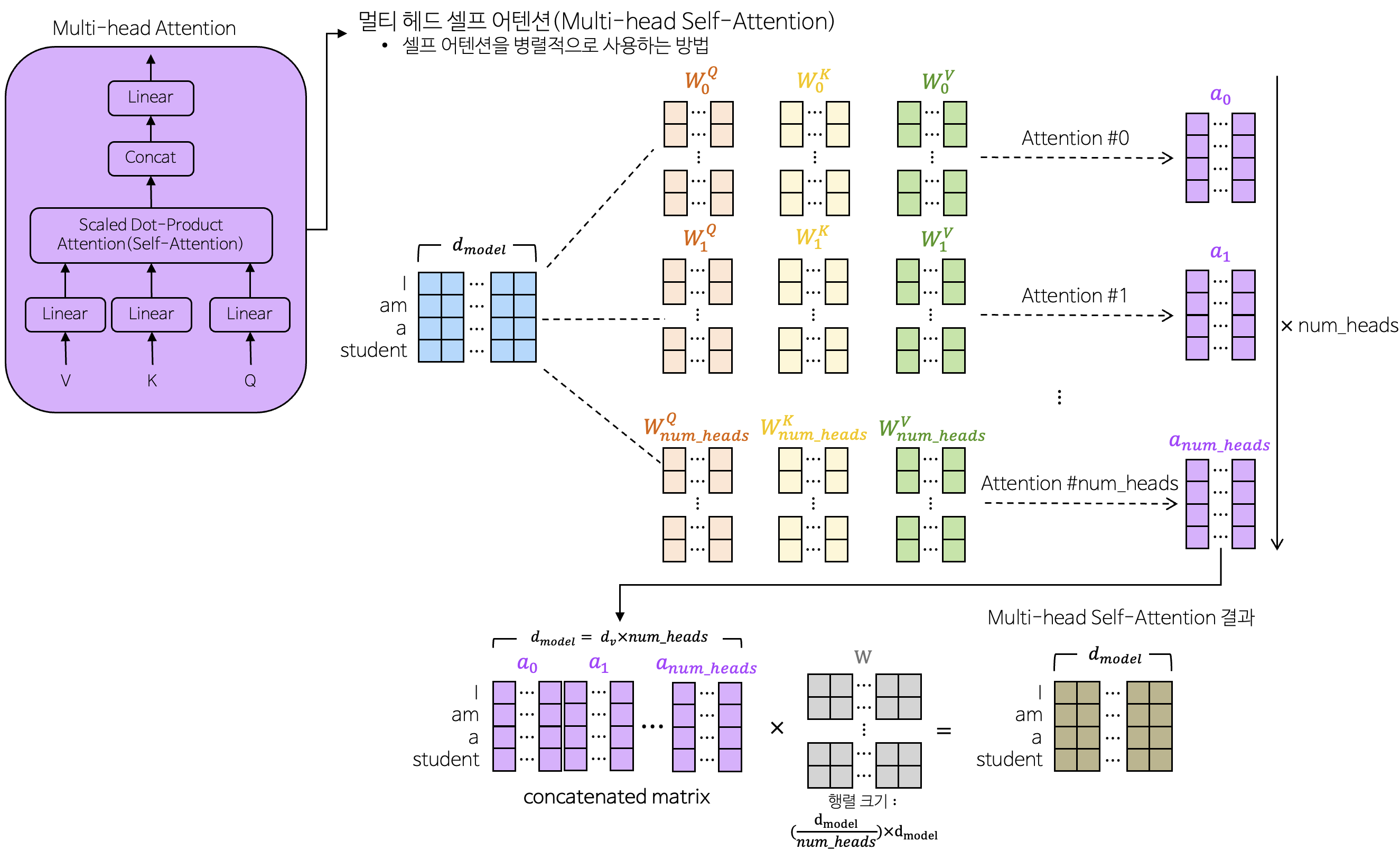
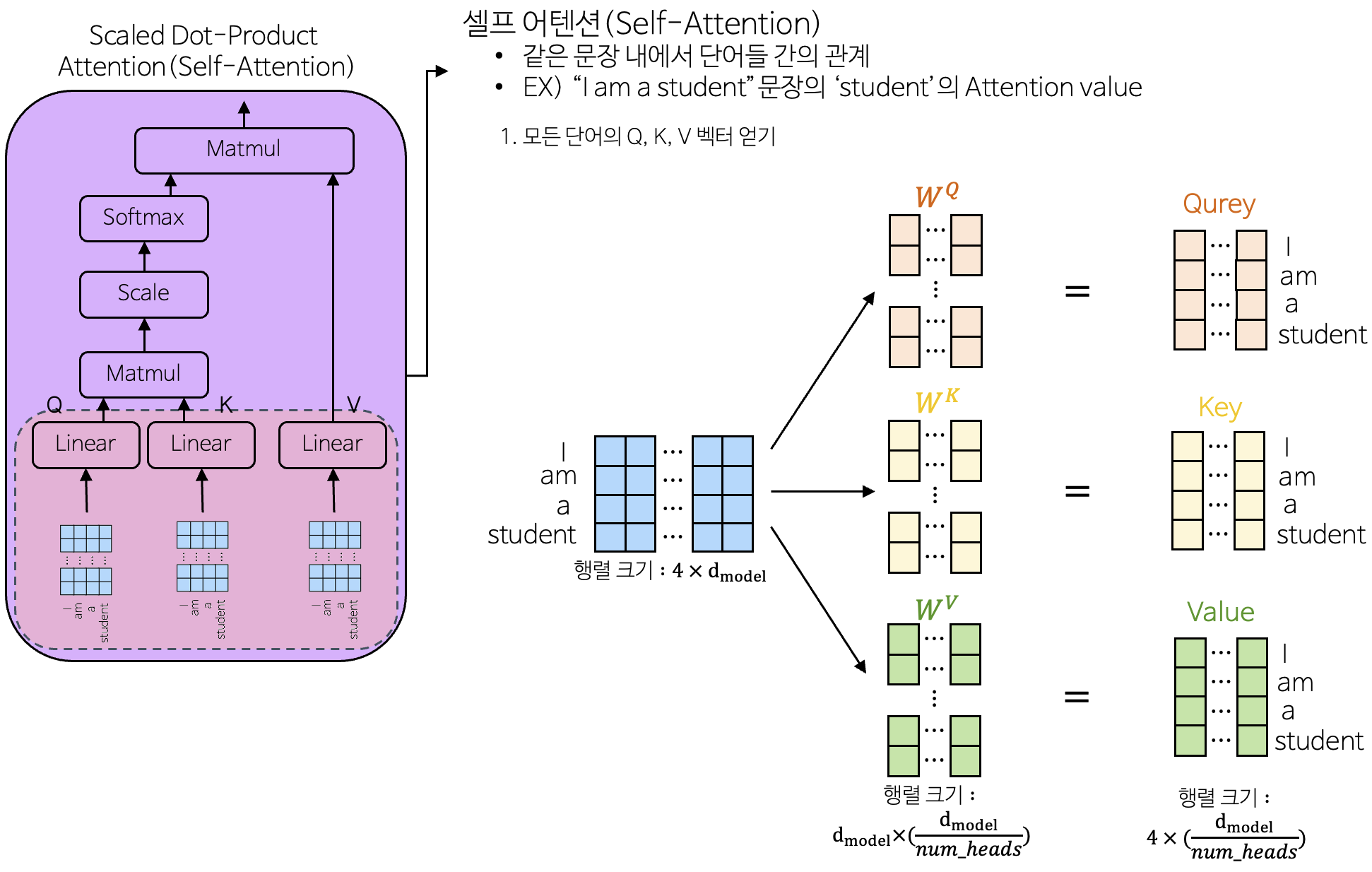
3-1-2-1. Self-Attention
- 같은 문장 내에서 단어들 간의 관계의 정보를 추출하는 데 사용
- 길이가 긴 시퀀스에서도 중요한 의존성을 보존함
- 어텐션의 목표는 value를 통하여 가중치 합계를 계산하는 것
- Query : 찾고자 하는 단어
- Key : 사전에 있는 단어
- Value : 사전에 있는 단어의 뜻
- Query와 Key가 유사한 만큼 Value를 가져옴

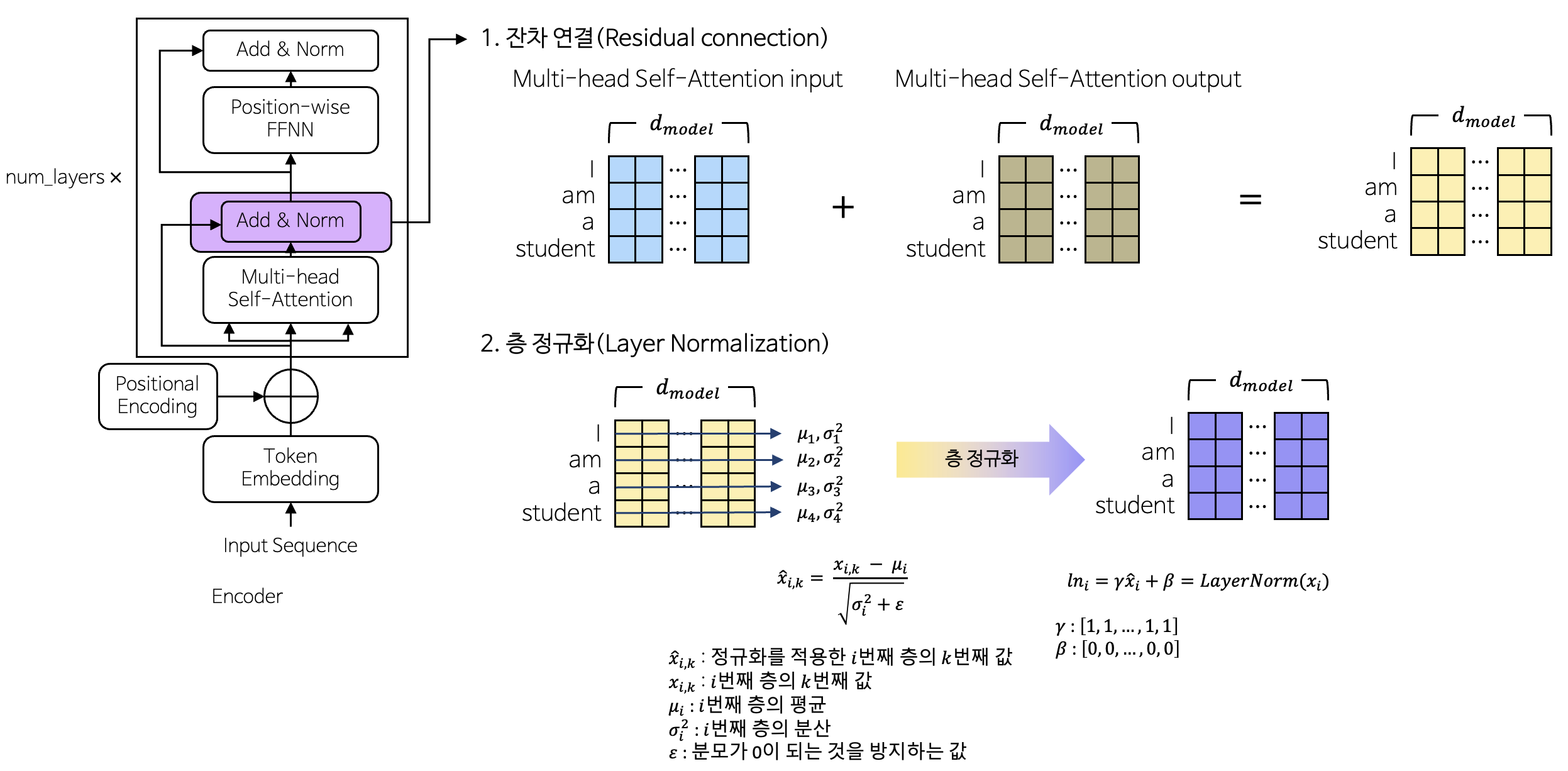
3-1-3. 잔차 연결(Residual Conection) & 정규화(Layer Normalization)
- 잔차 연결
- 처음 정보를 상기시켜 깊은 네트워크에서 기울기 소실 문제를 완화하고, 정보의 흐름을 원활하게 함
- 레이어 정규화
- 훈련 과정에서 각 층의 입력 분포를 정규화하여 학습을 안정화하고, 학습 속도를 향상시킴
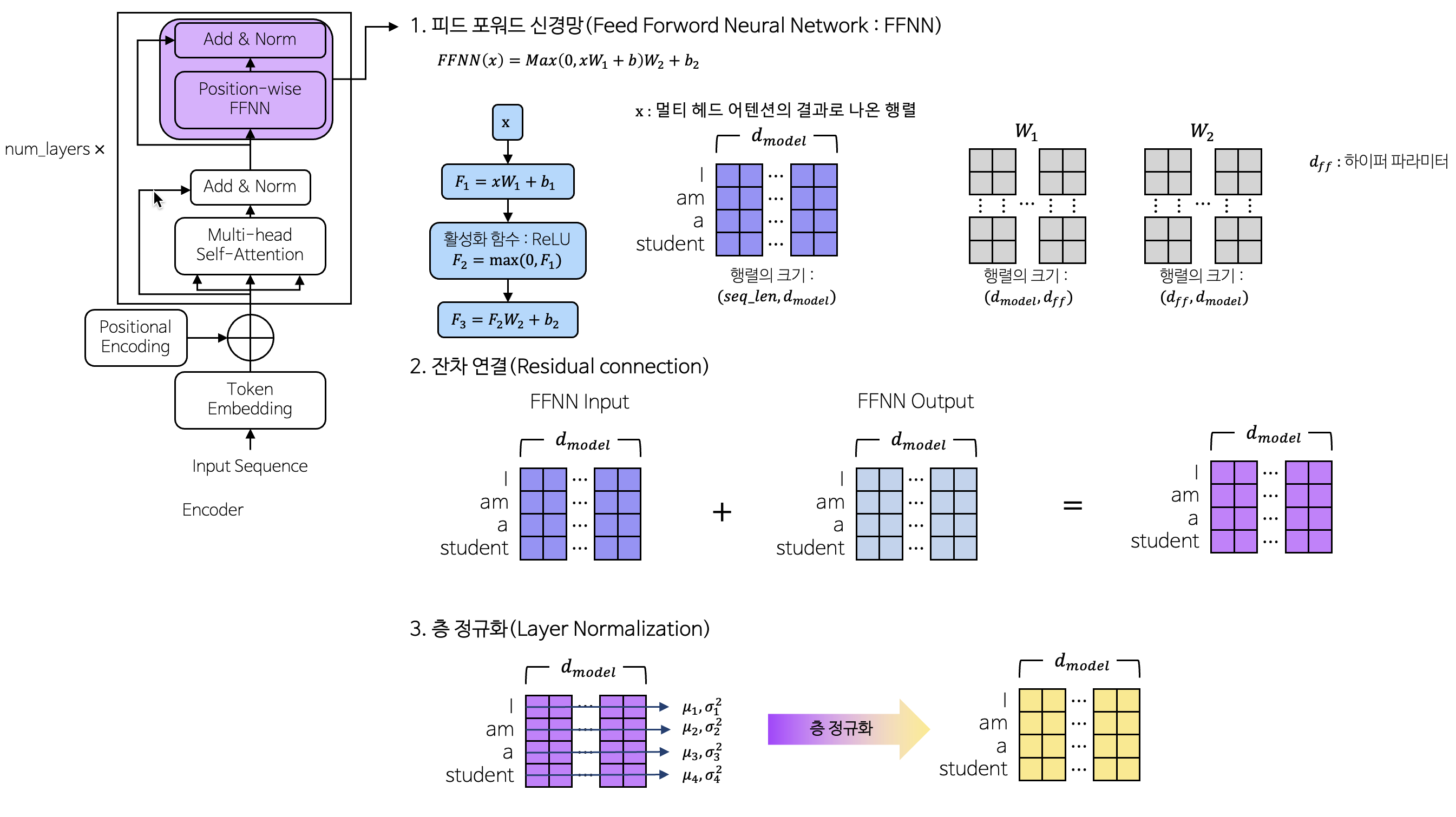
3-1-4. 피드 포워드 신경망(Feed forward network) & 잔차연결 & 정규화
- 피드 포워드 신경망
- 각 토큰의 정보를 개별적으로 처리하고, 비선형 변환을 통해 모델의 복잡한 패턴을 학습하기 위해 사용
3-2. Decoder
3-2-1. 토큰 임베딩 & 위치 인코딩
3-2-2. 마스크 멀티 헤드 어텐션 & 인코더-디코더 멀티 헤드 어텐션
This post is licensed under CC BY 4.0 by the author.