컴퓨터가 이해하는 정보
컴퓨터가 이해하는 정보
- CPU는 기본적으로 0과 1만을 이해할 수 있음
- 비트(bit) : 0과 1을 나타내는 가장 작은 정보의 단위
$N$ 비트는 $2^N$개의 정보를 표현 가능
1 byte 8 비트 1 kB 1,000 바이트 1 MB 1,000 킬로바이트 1 GB 1,000 메가바이트 1 TB 1,000 기가바이트 - 프로그램의 관점에서 본 정보 단위
- 워드(word) : CPU가 한 번에 처리할 수 있는 데이터의 크기
- ex) CPU가 한 번에 16비트를 처리할 수 있으면 1워드(word)는 16비트
1
2
3
4
5
6
7
8
a = 0.1
b = 0.2
c = 0.3
if a + b == c:
print("Equal")
else:
print("Not Equal")
1
Not Equal
- 컴퓨터 내부에서는 소수점을 나타내기 위해 대표적으로 부동 소수점(floating point) 표현 방식을 이용하는데, 이 방식의 정밀도에 한계가 있음.
- 부동 소수점 : 소수점이 고정되어 있지 않은 소수 표현 방식
- 필요에 따라 소수점의 위치가 이동할 수 있고 유동적(floating)이라는 의미에서 부동 소수점
- 부동 소수점 : 소수점이 고정되어 있지 않은 소수 표현 방식
- 지수(exponent)와 가수(significand)
- ex) $1231.23\ \times\ 10 ^ {-1}$ → $-1$ : 지수, $1231.23$ : 가수
- IEEE 754 : 부동 소수점 저장 방식
- 2진수의 지수와 가수를 아래와 같은 형식으로 저장
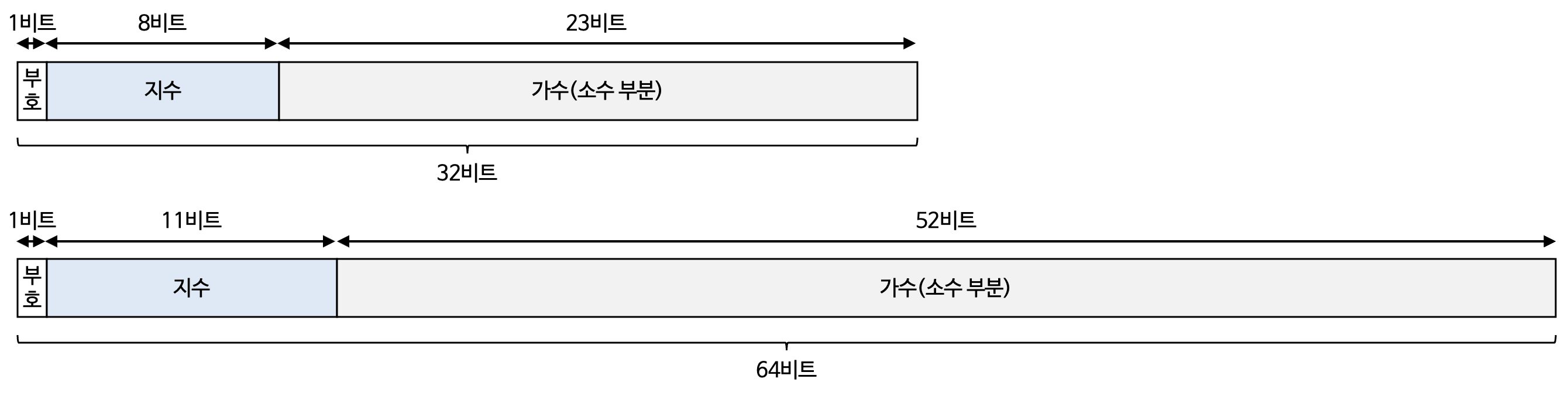
- 부호(sgin) 비트가 0이면 양수를 의미, 1이면 음수
- 가수의 정수부에는 1로 통일된 정규화한 수(normalized number)가 저장됨
- 즉, 가수는 1.___의 형태
- $2^{지수}\ \times \ 1.___$형태의 소수를 저장할 때 지수와 ___에 해당하는 소수 부분(fraction)만 저장
ex) $1.1010111010101 \times 2^6$
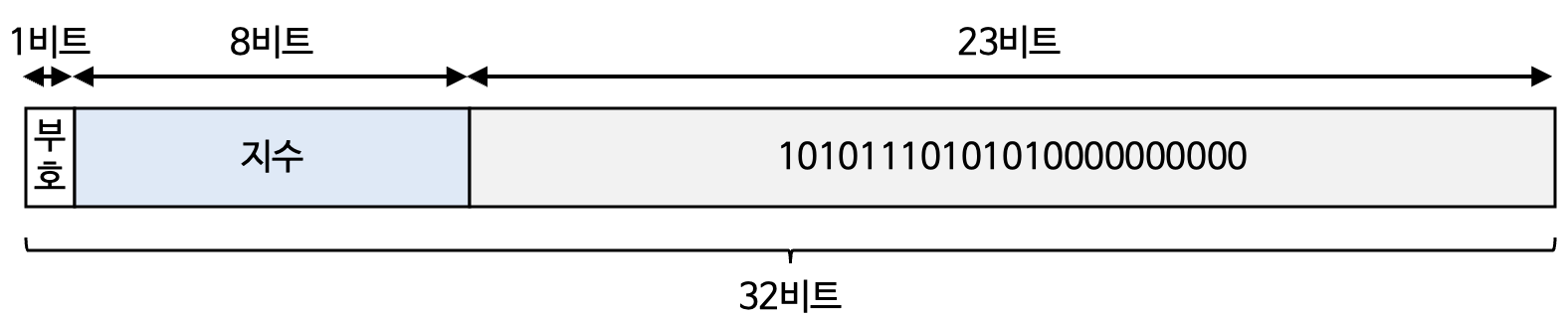
컴퓨터가 지수를 저장 할 때는 바이어스(bias) 값이 더해져서 저장
bias 값 : $2^{k-1}-1$ $k$ 는 지수의 비트 수
💡 10진수 소수를 2진수로 표현할 때, 10진수 소수와 2진수 소수의 표현이 딱 맞아떨어지지 않을 수 있음
- ex) 0.33333… 같은 소수
- 이러한 이유 때문에 일부 소수점을 생략하여 저장 → 위 코드에서 Not Equal이 결과인 이유
❓ Python Code 0.1 + 0.2 = 0.30000000000000004인 이유는?
- 문자 집합(Character set) : 컴퓨터가 이해할 수 있는 문자들의 집합
- 문자 인코딩(character encoding) : 문자 집합에 속한 문자를 컴퓨터가 이해하는 0과 1로 이루어진 문자 코드로 변환하는 과정
- 문자 디코딩(character decoding) : 0과 1로 표현된 문자를 사람이 이해하는 문자로 변환하는 과정
- 아스키(ASCII, American Standard Code for Information Interchange) : 가장 기본적인 문자 집합
- 영어 알파벳, 아라비아 숫자, 일부 특수문자 포함
- 아스키 문자를 표현하기 위해 8비트(1바이트) 사용
- 8비트 중 1 비트는 패리티 비트(parity bit) : 오류 검출을 위해 사용되는 비트
- 실질 적으로 문자 표현을 위해 사용되는 비트는 7비트 == $2^7$
- 코드 포인트(code point) : 문자 인코딩에서 ‘글자에 부여된 고유한 값’
- ‘A’의 코드 포인트 65
- 한글을 표기할 수 없음
- EUC-KR : KS X 1001, KS X 1003이라는 문자 집합 기반의 인코딩 방식(2,350개 정도 한글 단어 표현)
- 아스키 문자를 표현할 떄는 1바이트, 하나의 한 글자를 표현할 때는 2바이트 크기의 코드를 부여
- 아스키 코드 보다는 많은 단어를 표현 할 수 있지만, 모든 한글 조합 표현을 담을 수 없음. ex) ‘쀓’, ‘똠’
- 유니코드(unicode) : 많은 언어, 특수문자, 화살표, 이모티콘까지 코드로 표현할 수 있는 통일된 문자 집합
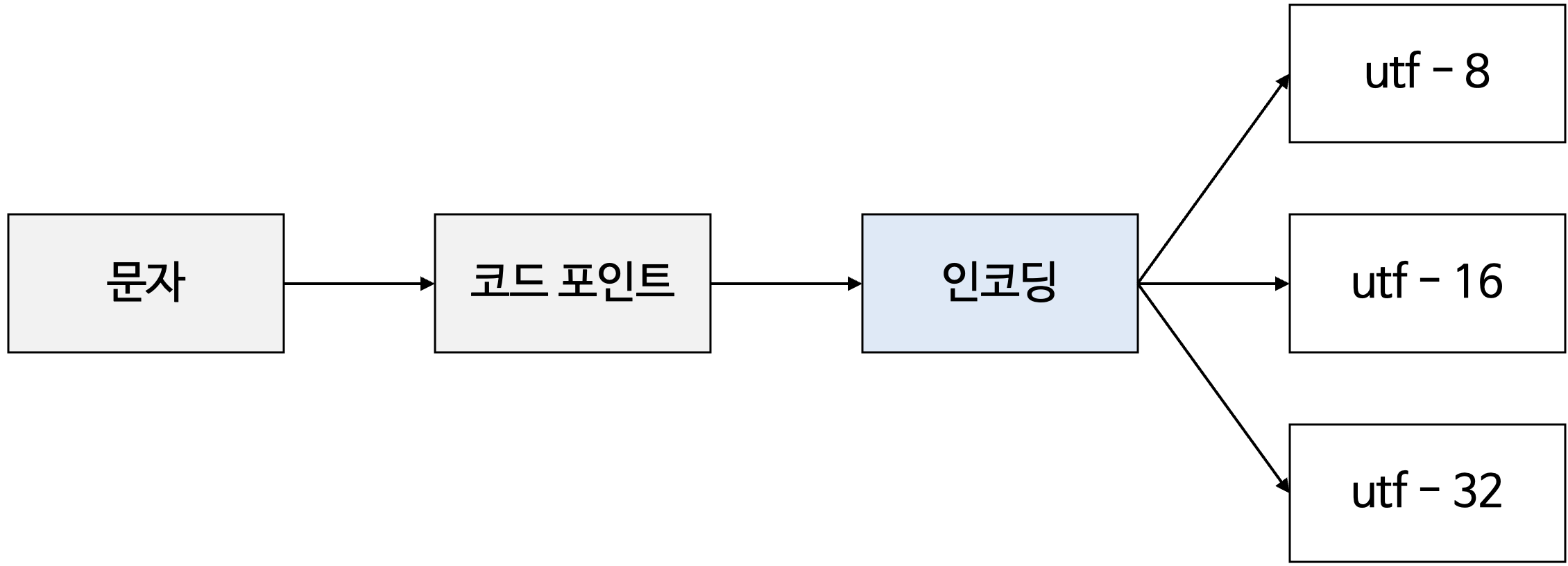
- 아스키 코드나 EUC-KR은 글자에 부여된 값을 그대로 인코딩 값으로 삼지만, 유니코드는 글자에 부여된 값 자체를 다양한 방법으로 인코딩 함.
- 유니코드 문자에 부여된 값을 인코딩하는 방식 : UTF-8, UTF-16, UTF-32 → 가변 길이 인코딩
- base64 인코딩 : 비단 문자뿐만 아니라, 이진 데이터 까지 변환할 수 있는 인코딩 방식
- 문자보다는 이진 데이터를 인코딩하는데 많이 사용
- 이미지 등 단순 문자 이외의 데이터까지 모두 아스키 문자 형태로 표현 가능
- 64진법, 64진수 하나를 표현하기 위해서는 $2^6$의 지수인 6비트가 필요
부족한 부분 0으로 패딩되어 ‘=’로 인코딩 됨.
- 명령어
- 수행할 동작
- 데이터 자체, 데이터가 저장된 위치
- 연산 코드(opcode) : 명령어가 수행할 동작
- 오퍼랜드(operand) : 동작에 사용될 데이터가 저장된 위치
- 즉, 하나의 명령어는 연산 코드와 0개 이상의 오퍼랜드로 구성
- 연산 코드는 연산자, 오퍼랜드는 피연산자라고도 부름
- 연산 코드 필드 : 명령어에서 연산 코드가 담기는 영역
- 오퍼랜드 필드 (== 주소 필드 address field) : 오퍼랜드가 담기는 영역
- 수행할 동작
- 기계어(machine code) : CPU가 이해할 수 있도록 0과 1로 표현된 정보를 있는 그대로 표현한 언어
- 어셈블리어(assembly language) : 0과 1로 표현된 기계어를 읽기 편한 형태로 단순 번역한 언어
1
2
3
int square(int num){
return num * num;
}
- 명령어 사이클(instruction cycle) : CPU가 명령어를 처리하는 과정에서 프로그램 속 각각의 명령어들의 일정한 주기
- 인출 사이클(fetch cycle) : 메모리에 있는 명령어를 CPU로 가지고 오는 단계
- 실행 사이클(execution cycle) : CPU로 가져온 명령어를 실행하는 단계
- 간접 사이클(indirect cycle) : 명령어를 실행하기 위해 한 번 더 메모리에 접근하는 단계
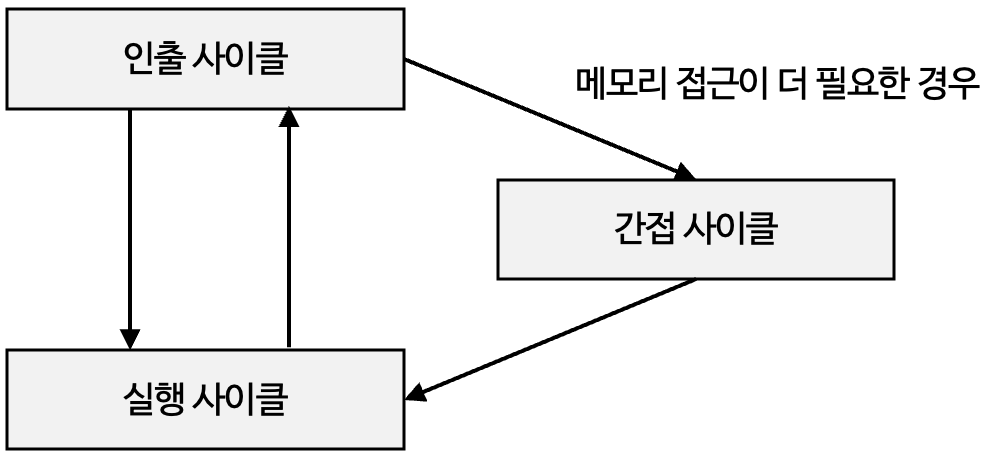
- 인터럽트 사이클(Interrupt Cycle) : CPU가 명령어를 실행 중(혹은 사이) 인터럽트 요청을 확인하고, 처리할 준비를 하는 주기
- 즉, “일단 내가 하던 일을 잠시 멈추고 인터럽트를 처리하자”라는 단계
This post is licensed under CC BY 4.0 by the author.