
Scikit-Learn
1. Scikit-learn 정의
-> 파이썬 머신러닝 라이브러리 중 가장 많이 사용되는 라이브러리
특징
- 개발을 위한 편리한 프레임워크와 API를 제공
- 머신러닝을 위한 다양한 알고리즘 존재
- Easy
conda install scikit-learn
import sklearn
2. Scikit-learn의 주요 기능
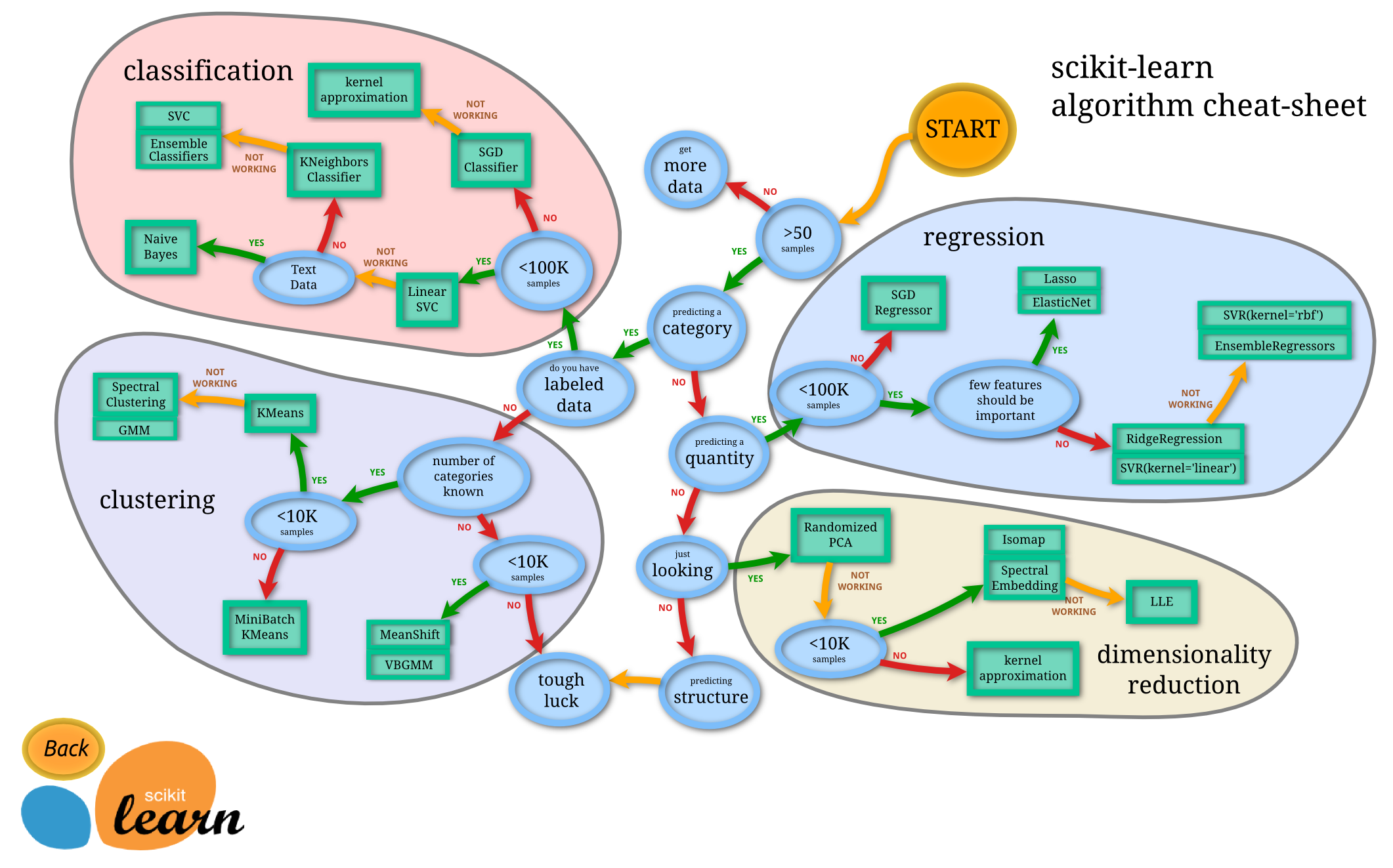
1. Example Data
- sklean.datasets : 사이킷런에 내장되어 예제로 제공하는 데이터 세트
- datasets.load_boston( ) : 미국 보스턴의 집 피처들과 가격에 대한 데이터 셋 [ 회귀 ]
- datasets.load_breast_cancer( ) : 위스콘신 유방암 피처들과 악성/음성 레이블 데이터 셋 [ 분류 ]
- datasets.load_diabets( ) : 당뇨 데이터 셋 [ 회귀 ]
- datasets.load_digits( ) : 0에서 9까지 숫자의 이미지 픽셀 데이터 셋 [ 분류 ]
- datasets.load_iris( ) : 붓꽃 용도이며, 붗꽃에 대한 피처를 가진 데이터 셋 [ 분류 ]
- Key
- data : 피처의 데이터 셋
- target : 분류 시 레이블 값, 회귀 일때는 숫자 결과 값 데이터 셋
- target_names : 개별 레이블 이름
- feature_names : 피처의 이름
- DESCR : 데이터 셋트에 대한 설명과 각 피처의 설명
2. Feature 처리
-
skelarn.preprocessing : 데이터 전처리에 필요한 다양한 가공 기능 제공
-
데이터 인코딩
-
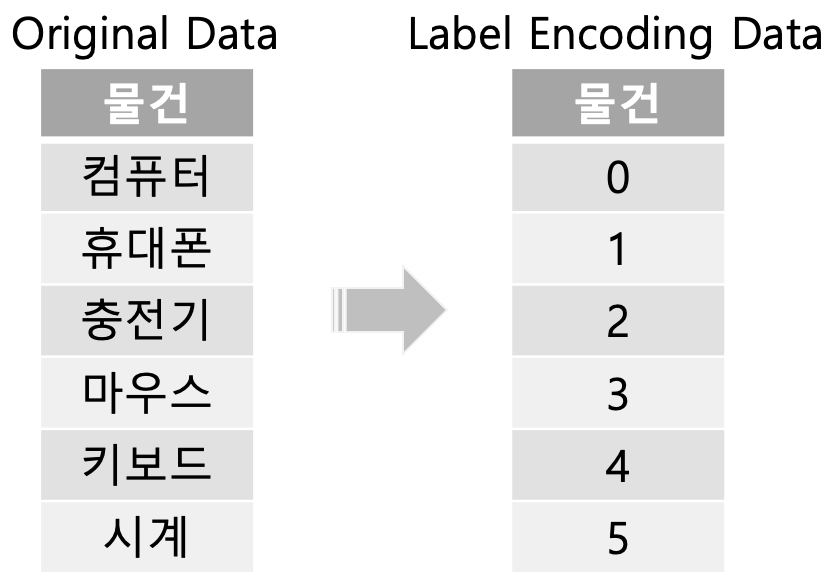
레이블 인코딩(LabelEncoding)
-
간단하게 문자열 값을 숫자형 카테고리 값으로 변환하는 것
-
카테고리가 많을 수록 숫자가 커짐 -> 가중치 문제
-
-
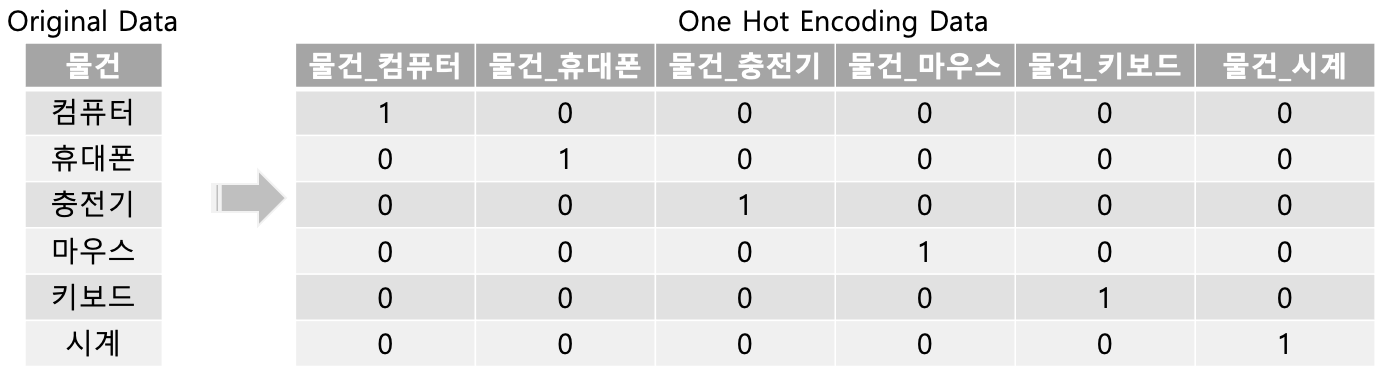
원 핫 인코딩(One Hot encoding)
-
피처 값의 유형에 따라 새로운 피처를 추가해 고유 값에 해당하는 칼럼에만 1을 하고 나머지 컬럼에는 0을 표시하는 방식
-
-
-
피처 스케일링과 정규화
- Feature Scaling
- 표준화(Standardization)
- StandardScaler
- 데이터의 피처 각각이 평균이고 0이고 분산이 1인 가우시안 정규 분포를 가진 값으로 변환하는 것
- 사이킷런에서 구현한 RBF커널을 이용하는 서포트 벡터 머신(Support Vector Machine) or 선형 회귀(Linear Regression) or 로지스틱 회귀(Logistic Regression)는 가우시안 분포를 가지고 있다고 구현되었기 때문에 사전에 표준화를 적용하는 것은 예측 성능 향상에 중요한 요소가 될 수 있음
- MinMaxScaler
- 데이터값을 0과 1사이의 범위 값으로 변환(음수 값이 있으면 -1에서 1값으로 변환)
- 데이터의 분포가 가우시안 분포가 아닌 경우에는 Min, Max Scale 을 적용해 볼 수 있음
- StandardScaler
- 정규화(Normalization)
- 서로 다른 피처의 크기를 통일하기 위해서 크기를 변환하는 것
- 표준화(Standardization)
- Feature Scaling
-
-
sklearn.feature_selection : 중요한 feature를 우선순위로 선택하기 위한 수행 기능 제공
-
learn.feature_extraction : 데이터의 벡터화된 feature 추출 기능 제공
3. Feature 처리 & 차원 축소
- sklearn.decomposition : 차원 축소와 관련된 알고리즘 제공
4. 데이터 셋 분리, 파라미터 튜닝
- sklearn.model_selection
- train_test_split( )
- test_size : 전체 데이터에서 테스트 데이터 세트 크기 [ Default : 0.25(25%) ]
- train_size : 전체 데이터에서 학습 데이터 셋 크기
- shuffle : 데이터를 분리하기 전에 데이터를 미리 섞을지를 결정 [ Default : True ]
- random_state : 난수 값
- GridSearchCV
- estimator : classifier, regressor, pipeline, etc
- param_grid : key + 리스트 값을 가지는 딕셔너리
- estimator의 튜닝을 위해 파라미터명과 사용될 여러 파라미터 값을 지정
- scoring : 예측 성능을 측정할 평가 방법을 지정
- accuracy
- cv : 교차 검증을 위해 분할되는 학습/테스트 세트의 개수를 지정
- refit : [ Default : True ] 생성 시 가장 최적의 하이퍼 파라미터를 찾은 뒤 입력된 estimator 객체를 해당 하이퍼파라미터로 재학습 시킴
- train_test_split( )
5. 평가 ( Evaluation )
- sklearn.metrics: Classification, Regression, Clustering etc 성능 측정방법
6. MachineLearning Algorithm
- sklearn.ensemble : 앙상블
- sklearn.linear_model : Regression(선형 회귀 및 로지스틱 회귀)
- sklearn.naive_bayes : 나이브 베이지안
- sklearn.neighbors : 최근접 법
- sklaern.svm : 서포트 벡터 머신(Support Vector Machine)
- sklearn.tree : 의사결정 나무
- sklearn.cluster : 클러스터링
3. Estimator
Estimator = 분류(Classifier) + 회귀(Regressor)
I. 분류(Classifier)
- DecisionTreeClassifier
- RandomForestClassifier
- GradientBoostingClassifier
- GasussianNB
- SVC(Stochastic gradient descent)
II. 회귀(Regressor)
- LinearRegression
- Ridge
- Lasso
- RandomForsetRegressor
- GradientBoostingRegressor
4. 예제를 통한 모델 구축
■ 모델 구축 순서
I. 데이터 세트 분리
II. 모델 학습
III. 예측 수행
IV. 평가