DataPartitioning(with R)
데이터 분할(Data Partitioning)
1. 데이터 분할을 하는 이유
-
관측된 데이터를 모두 학습 데이터로 사용하여 예측을 한다면?
1. 과소적합(Underfitting)
-
모델이 충분히 복잡하지 않아 학습 데이터의 구조/패턴을 정확히 반영하지 못하는 문제

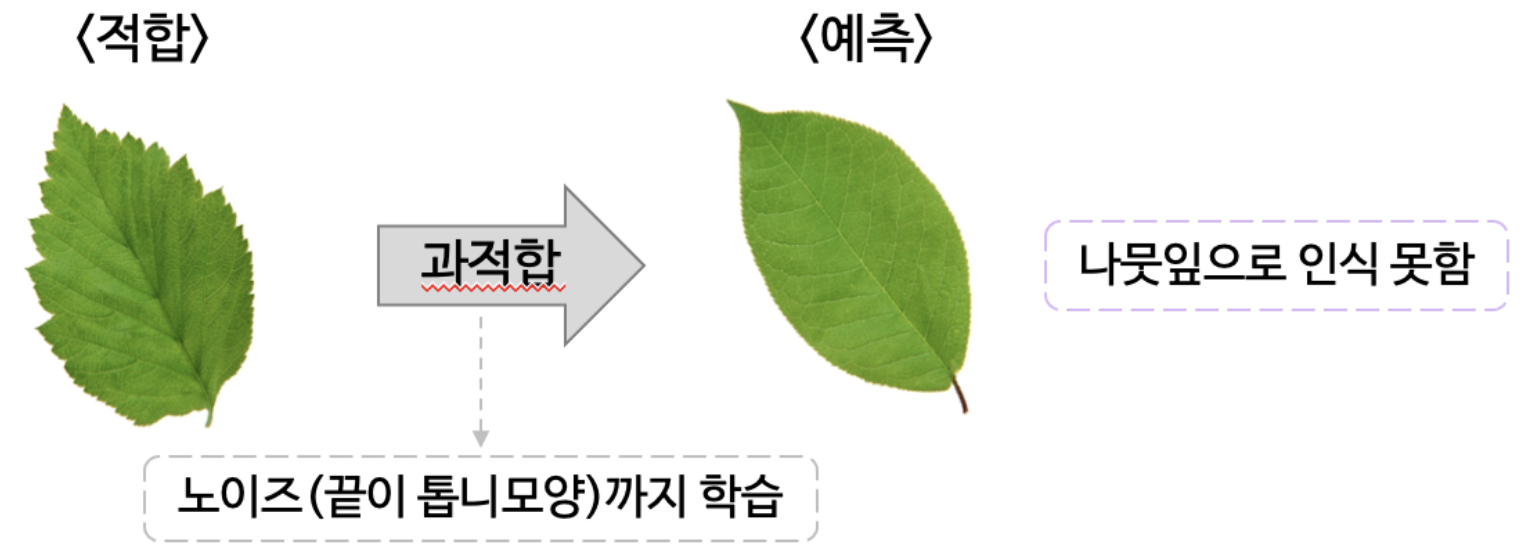
2. 과적합(Overfitting)
-
모델이 복잡하고 지나치게 학습하여 학습 데이터셋에서는 모델 성능이 높게 나타나지만 새로운 데이터가 주어졌을 경울 정확한 예측/분류를 수행하지 못함
-
Traing data에 더 적합한 모형을 구출할수록 오분류율은 감소
- Training Data에만 적합된 모형이 구축됨으로써 모형이 복잡해질 수 있음
- 이 과정에서 좋은 모형이라고 착각
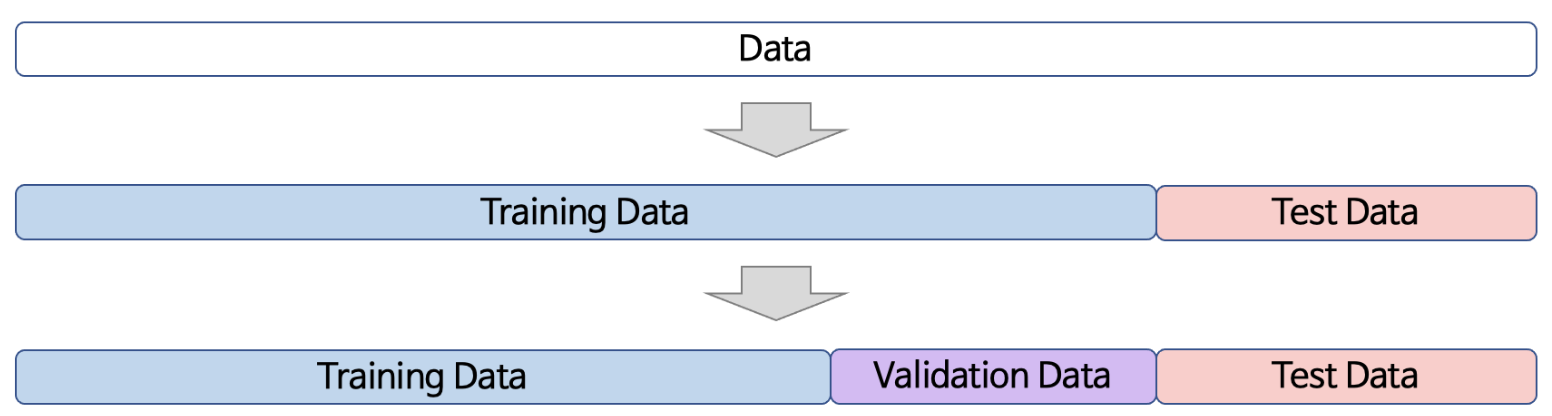
2. 과적합을 탐지하고 방지하기 위해 3가지로 분할
1. Training Data (60% ~ 70%)
- 모형 구축시 사용되는 데이터
- 예측 혹은 분류 모델을 훈련
2. Validation Data (Training Data의 약 30%)
- 모형의 모수들을 조정함으로써 최적의 모형 선택
- 학습 데이터로부터 구축된 여러 모형들의 성능을 비교할 때 사용
3. Test Data (30% ~ 40%)
-
모형 구축에 전혀 사용되지 않음
-
구축된 모형이 미래의 새로운 데이터에 대해 얼마만큼 예측/분류 성능을 보일지 평가할 때 사용
-
createDataPartition(y, times = *, p = *, list = TRUE/FALSE, ...)-
y : Target
-
times : 생성할 파티션 수
-
p : Training Data의 비율
-
list : 논리함수로 TRUE이면 list로 결과를 출력
-
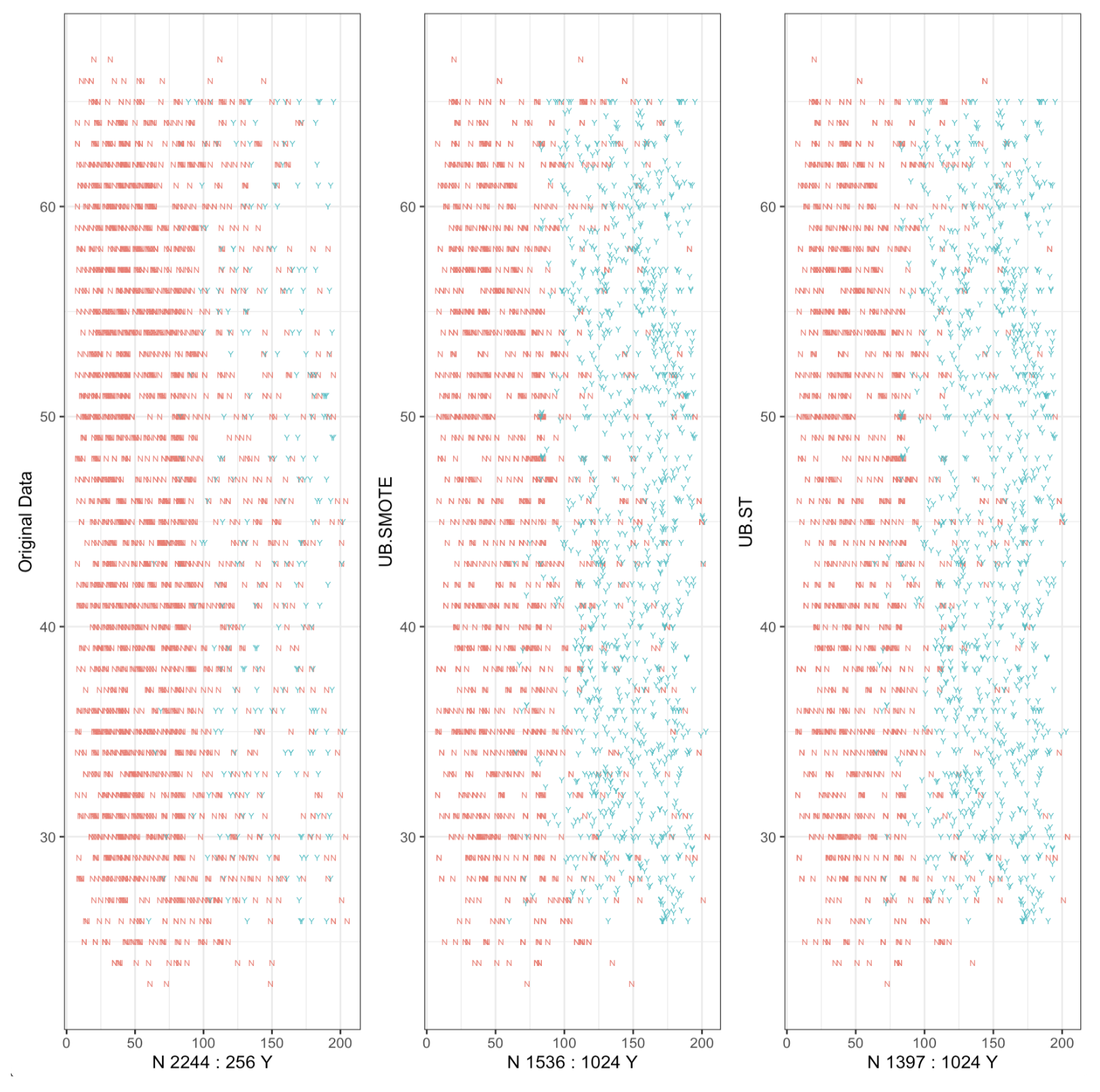
3. Unbalnaced Target
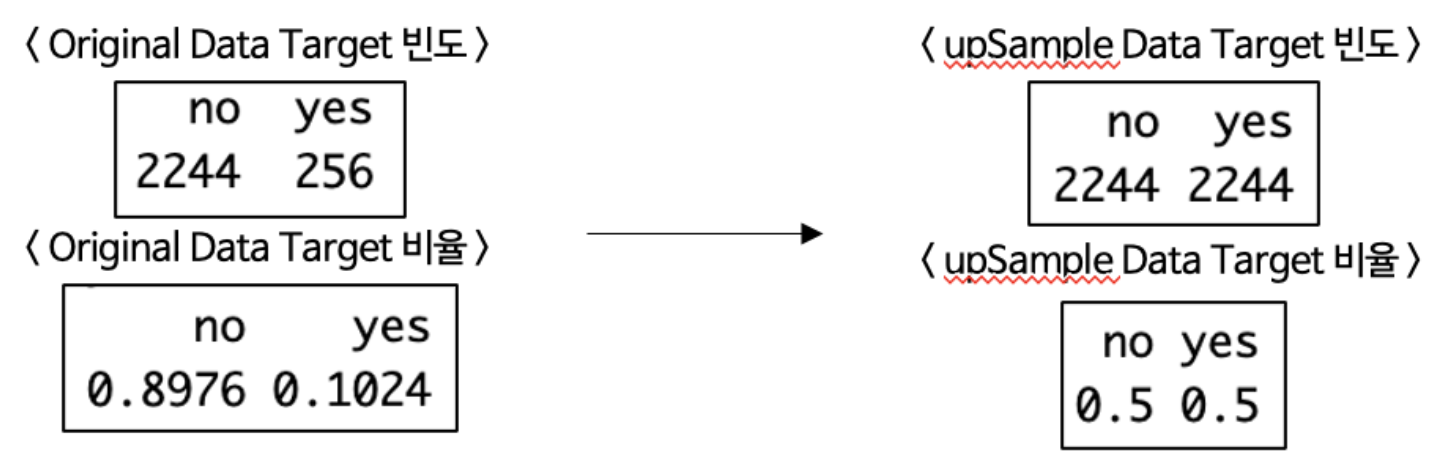
1. upSample
-
적은 쪽의 데이터를 중복 추출하여 균형을 맞춤 ➢ 과적합 가능성 높아짐
-
# package : caret upSample(x, y, ...)- x : 예측변수
- y : Target
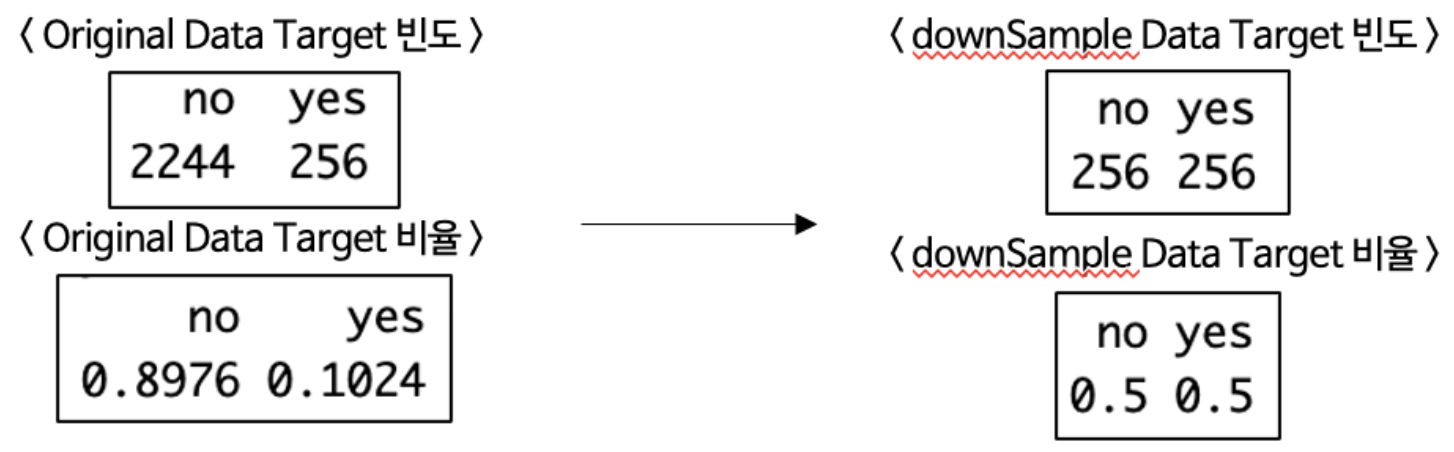
2. downSample
-
많은 쪽의 데이터를 적게 추출하여 균형을 맞춤 ➢ 정보 손실
-
# package : caret downSample(x, y, ...)- x : 예측 변수
- y : Target
3. SMOTE(Synthetic Minority Oversampling Techinique)
-
최근접 이웃 기법을 이용하여 점들을 추가 ➢ 근사적으로 1:1 매칭
-
Algorithm
I. 소수 클래스의 샘플을 추출
II. 추출된 샘플의 k 최근접 이웃을 발견
III. 추출된 샘플과 k 최근접 이웃 간 차이 (또는 거리) 계산
IV. 이 차이에 0 ~ 1사이의 임의의 값을 곱한 후 추출된 샘플에 더함
V. 훈련 데이터에 추가
-
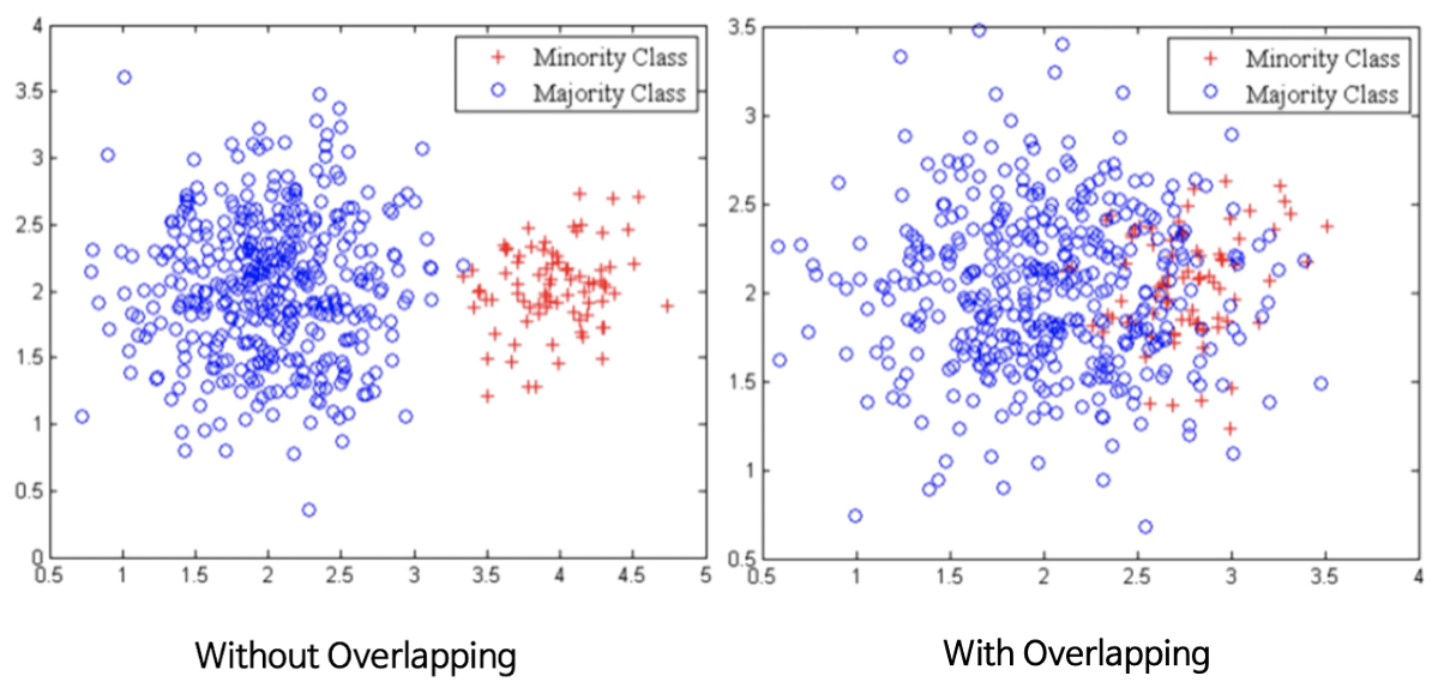
문제점
-
Overlapping
-
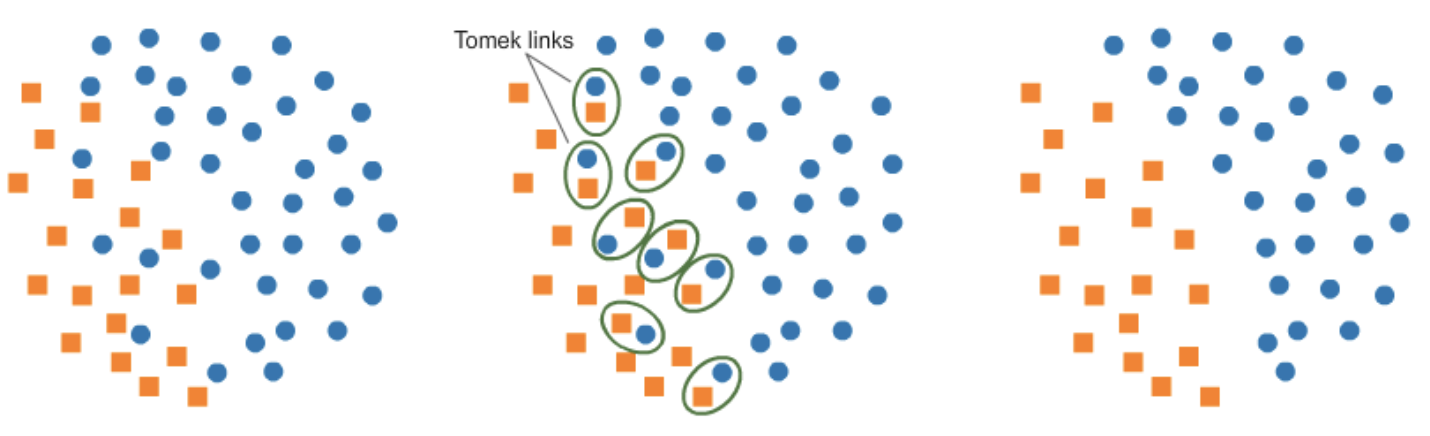
Tomek link
-
최소거리를 가지지만 서로 다른 클래스로 분류된 한 쌍(pair)의 데이터
- 가장 가까운 거리이면 같은 클래스로 구분되어야 함에도 불구하고 서로 다른 클래스로 구분됨(Noise)
-
두 표본 중 하나(다수 클래스) 또는 둘 다 노이즈(Noise)로 판단 ➢ Tomek Link로 구분하여 제거
출처 : 데이터 사이언스 스쿨 - 비대칭 데이터 문제
-
-
-
# package : DMwR SMOTE(form, data, k = *, perc.over = *, perc.under = *, ...)- form : 예측문제를 해결하는 공식
- data : 원래 데이터셋을 포함하는 데이터 프레임
- k : 고려할 최근접 이웃 수
- perc.over : 비율이 낮은 클래스에서 얼마나 추가로 샘플링해야 하는지 결정하는 수
- perc.under : 비율이 낮은 쪽의 데이터를 추가로 샘플링할 때 각 샘플에 대응해서 비율이 높은 쪽의 데이터를 얼마나 추가적으로 샘플링할지 결정하는 수
- SMOTE는 Target의 형태가 문자형만!

4. SMOTE ➢ Tomek
-
노이즈 (SMOTE 실행 후 발생) 제거 후 근사적으로 1:1 매칭
-
노이즈를 제거함으로써 SMOTE보다 더 좋은 결과
-
# package : unbalanced ubTomek(x, y, ...)- x : 예측 변수
- y : Target

5. SMOTE vs SMOTE+Tomek